Hystrix服务降级


hystrix中的重要概念:
1,服务降级
比如当某个服务繁忙,不能让客户端的请求一直等待,应该立刻返回给客户端一个备选方案
2,服务熔断
当某个服务出现问题,卡死了服务不可用了,不能让用户一直等待,需要关闭所有对此服务的访问(保险丝熔断电路跳闸)然后调用服务降级
3,服务限流
限流,比如秒杀场景,不能访问用户瞬间都访问服务器,限制一次只可以有多少请求
使用hystrix,服务降级:
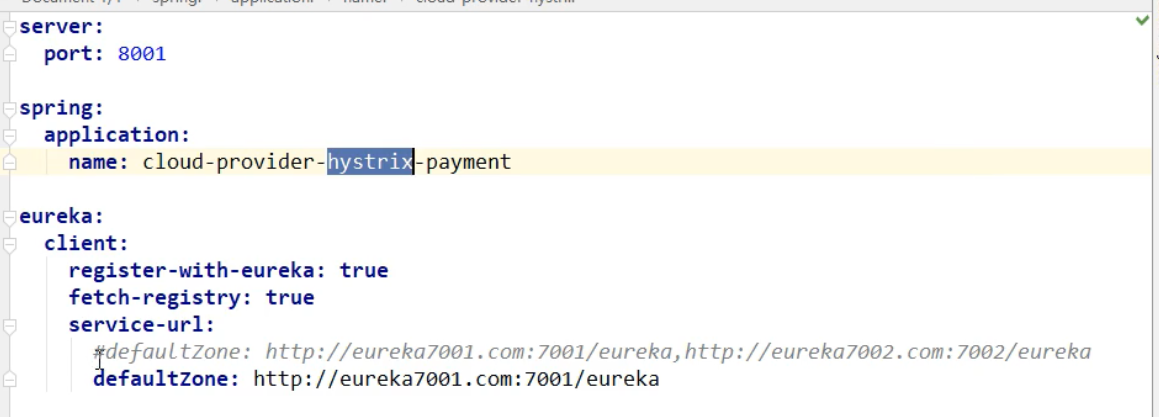
1,创建带降级机制的pay模块 :
名字: cloud-hystrix-pay-8007
2,pom文件
3,配置文件
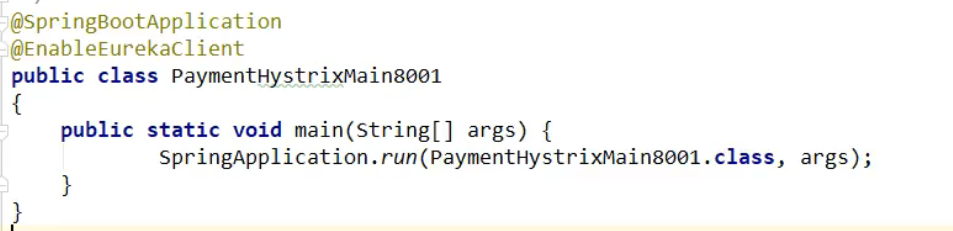
4,主启动类
5,service

6controller

7,先测试:
此时使用压测工具(如JMeter),并发20000个请求,请求会延迟的那个方法,
压测中,发现,另外一个方法并没有被压测,但是我们访问它时,却需要等待
这就是因为被压测的方法它占用了服务器大部分资源,导致其他请求也变慢了
8,先不加入hystrix,
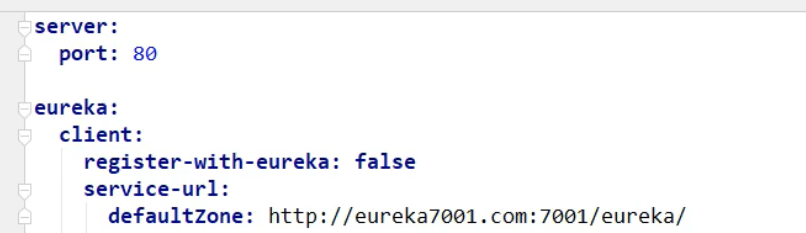
2,创建带降级的order模块:
1,名字: cloud-hystrix-order-80
2,pom
3,配置文件
4,主启动类

5,远程调用pay模块的接口:
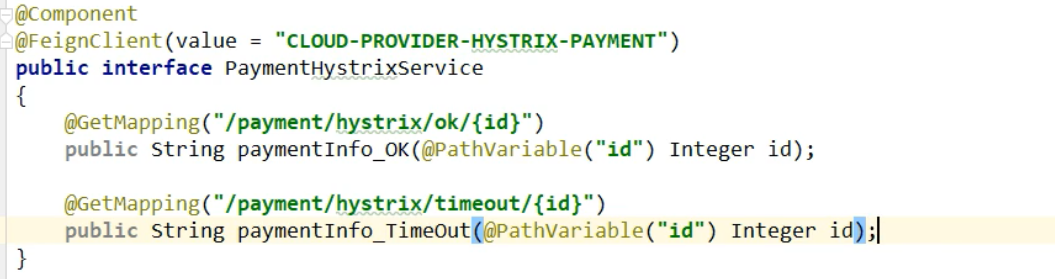
6,controller:
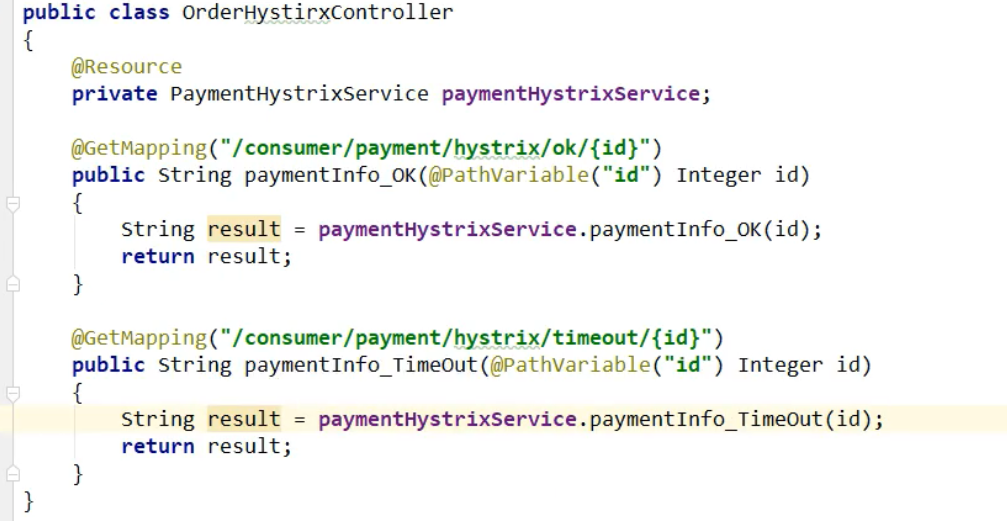
7,测试
启动order模块,访问pay
再次压测2万并发,发现order访问也变慢了

解决:


3,配置服务降级:
1,修改pay模块
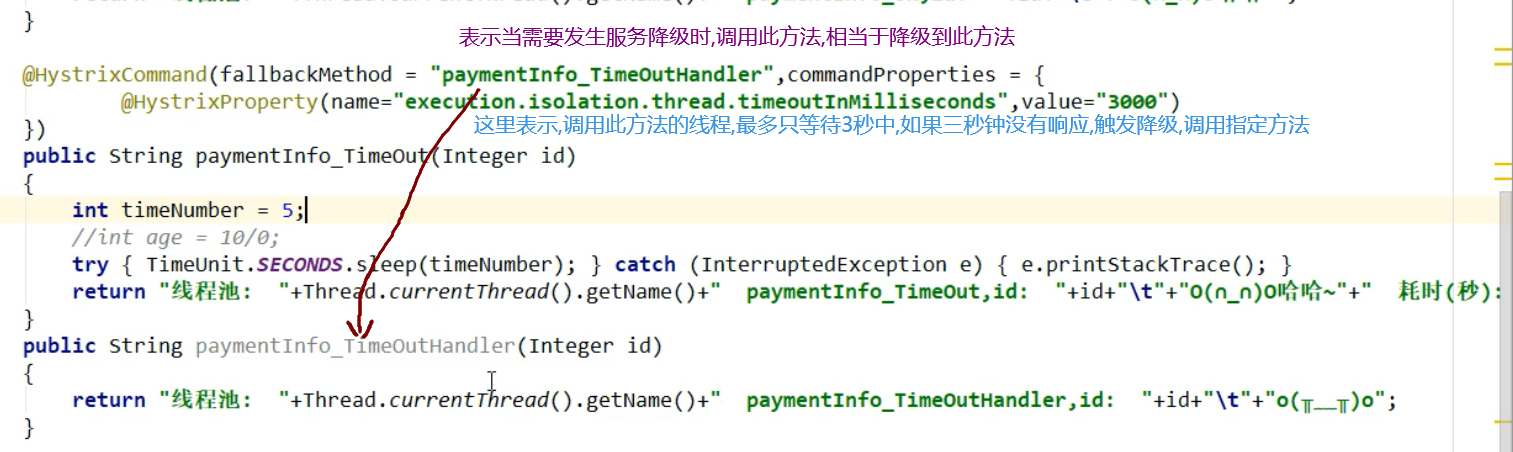
1,为service的指定方法(会延迟的方法)添加@HystrixCommand注解
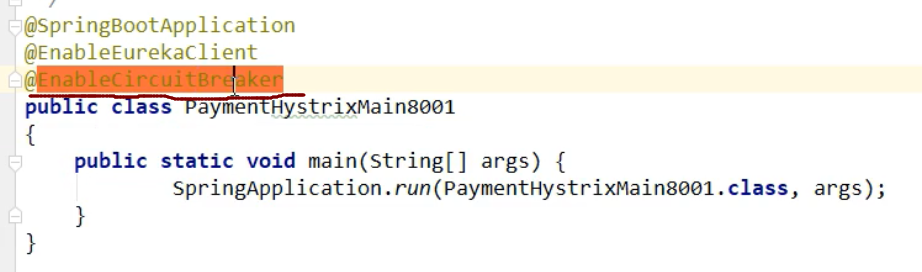
2,主启动类上,添加激活hystrix的注解
3,触发异常
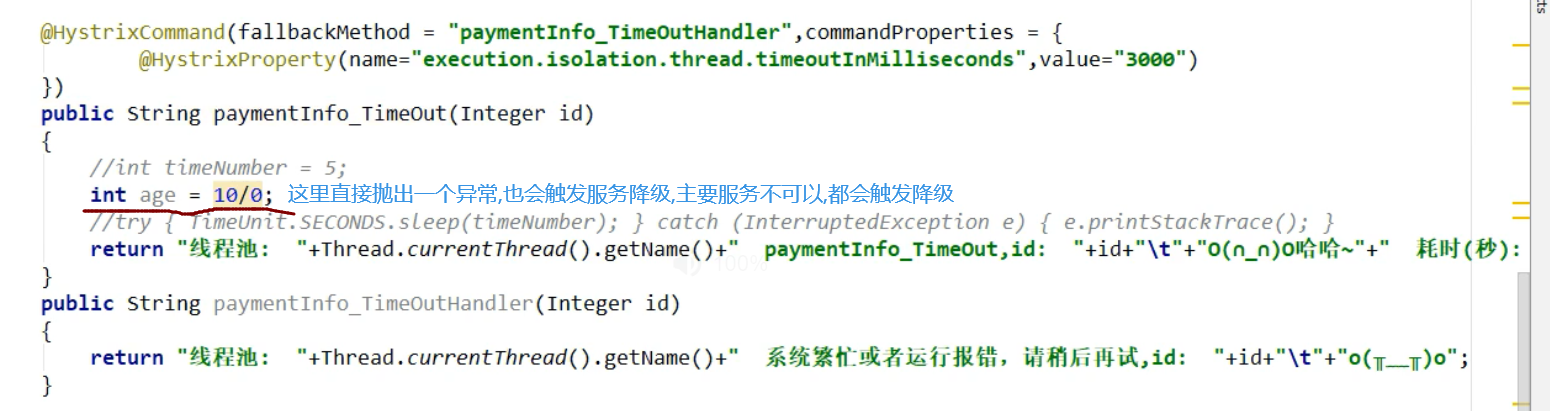
 可以看到,也触发了降级
可以看到,也触发了降级
2,修改order模块,进行服务降级
一般服务降级,都是放在客户端(order模块),

1,修改配置文件:
2,主启动类添加直接,启用hystrix:

3,修改controller,添加降级方法什么的

4,测试
启动pay模块,order模块,
注意:,这里pay模块和order模块都开启了服务降级
但是order这里,设置了1.5秒就降级,所以访问时,一定会降级
4,重构:
上面出现的问题:
1,降级方法与业务方法写在了一块,耦合度高
2.每个业务方法都写了一个降级方法,重复代码多
解决重复代码的问题:
配置一个全局的降级方法,所有方法都可以走这个降级方法,至于某些特殊创建,再单独创建方法
1,创建一个全局方法

2,使用注解指定其为全局降级方法(默认降级方法)


3,业务方法使用默认降级方法:
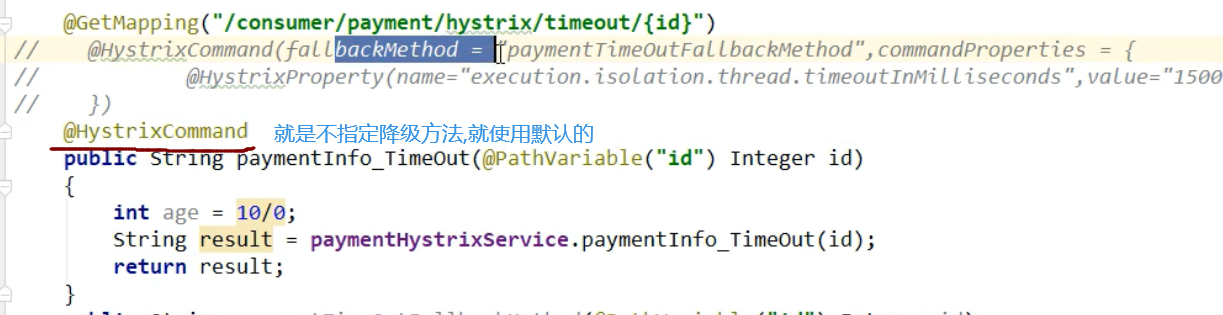
4,测试:

解决代码耦合度的问题:
修改order模块,这里开始,pay模块就不服务降级了,服务降级写在order模块即可
1,Payservice接口是远程调用pay模块的,我们这里创建一个类实现service接口,在实现类中统一处理异常
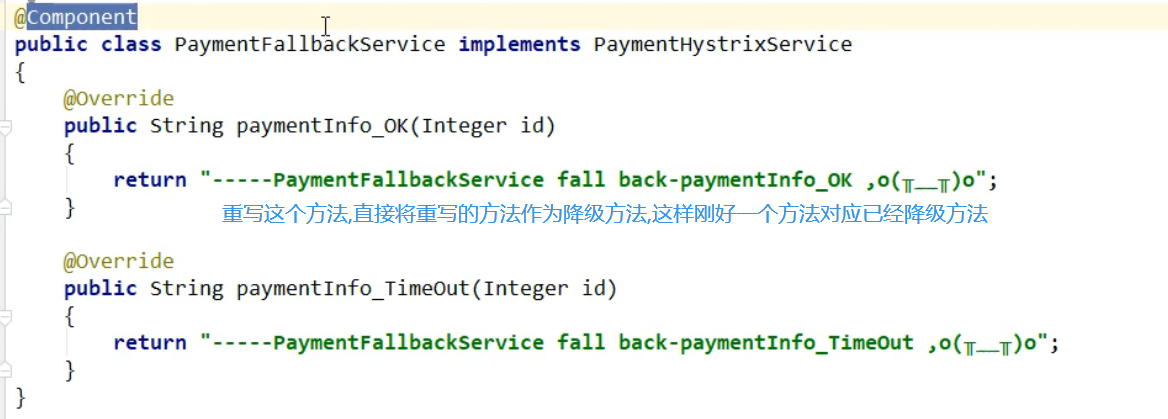
2,修改配置文件:添加:
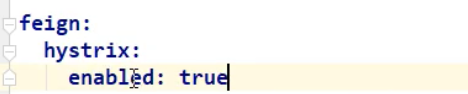
3,让PayService的实现类生效:
1 | 它的运行逻辑是: |
4,启动测试
启动order和pay正常访问—ok
==此时将pay服务关闭,order再次访问==

可以看到,并没有报500错误,而是降级访问==实现类==的同名方法
这样,即使服务器挂了,用户要不要一直等待,或者报错
问题:
这样虽然解决了代码耦合度问题,但是又出现了过多重复代码的问题,每个方法都有一个降级方法
使用服务熔断:

比如并发达到1000,我们就拒绝其他用户访问,在有用户访问,就访问降级方法

1,修改前面的pay模块
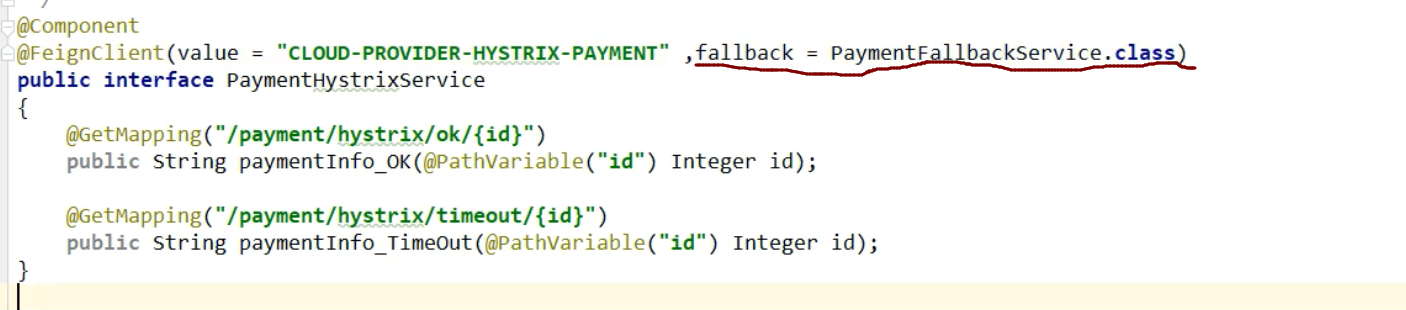
1,修改Payservice接口,添加服务熔断相关的方法:
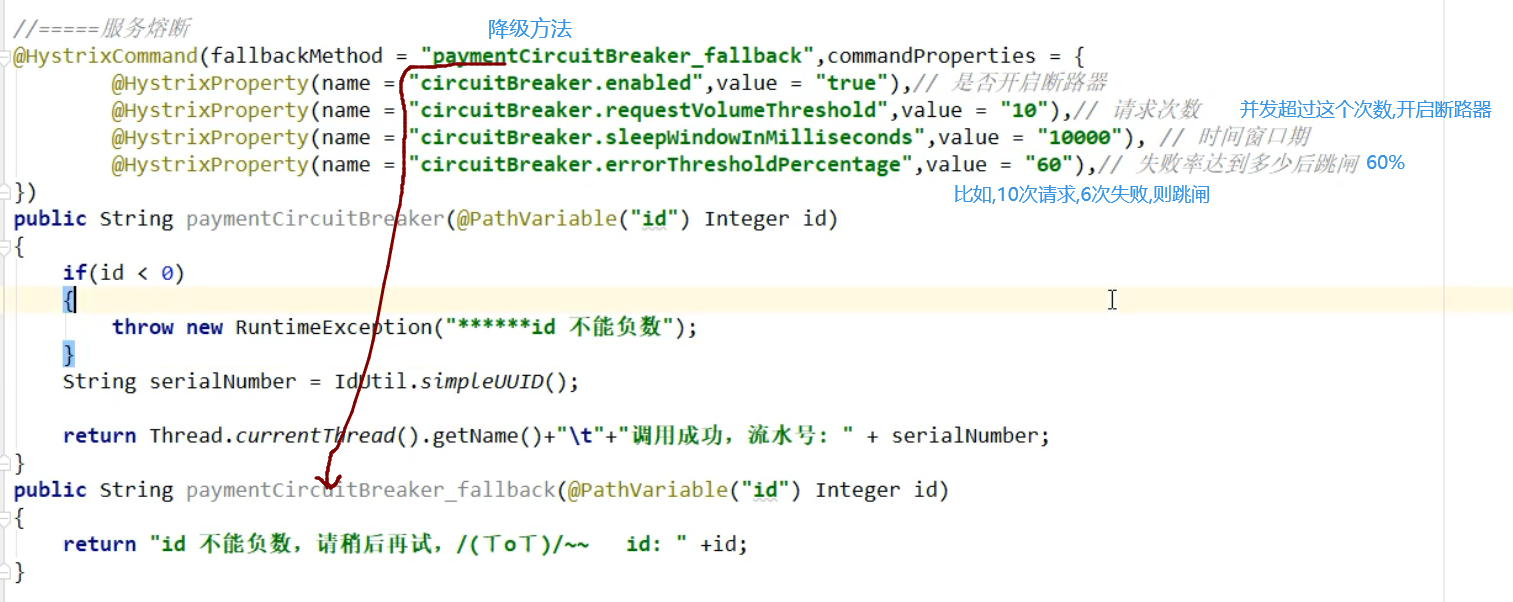
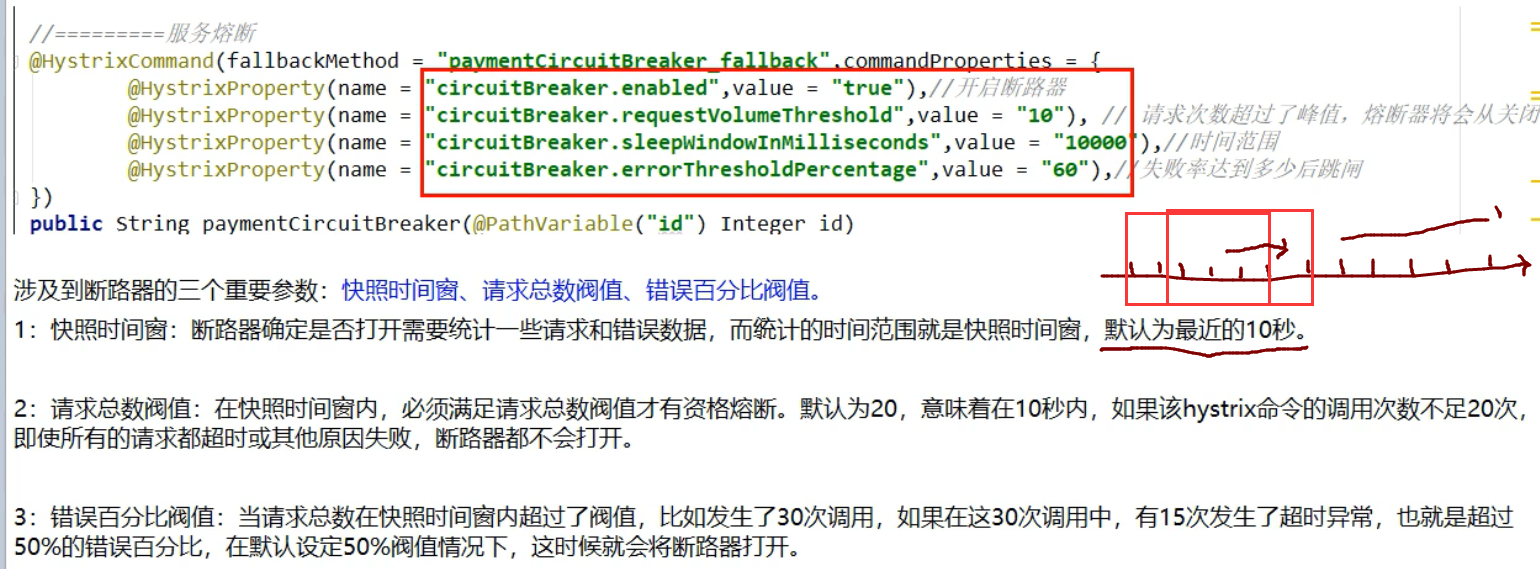
这里属性整体意思是:
10秒之内(窗口,会移动),如果并发==超过==10个,或者10个并发中,失败了6个,就开启熔断器
IdUtil是Hutool包下的类,这个Hutool就是整合了所有的常用方法,比如UUID,反射,IO流等工具方法什么的都整合了
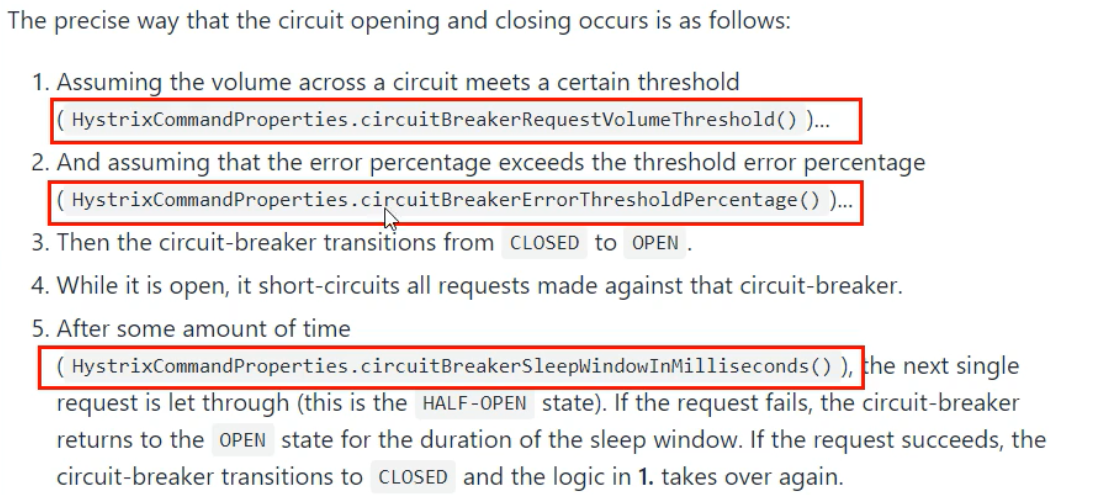
1 | 断路器的打开和关闭,是按照一下5步决定的 |
2,修改controller
添加一个测试方法;
3,测试:
启动pay,order模块
==多次访问,并且错误率超过60%:==

此时服务熔断,此时即使访问正确的也会报错:

但是,当过了几秒后,又恢复了
因为在10秒窗口期内,它自己会尝试接收部分请求,发现服务可以正常调用,慢慢的当错误率低于60%,取消熔断
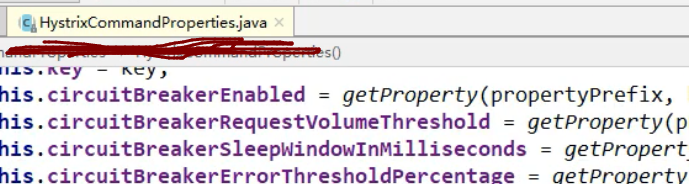
Hystrix所有可配置的属性:
全部在这个方法中记录,以成员变量的形式记录,
以后需要什么属性,查看这个类即可
总结:

==当断路器开启后:==

==其他参数:==




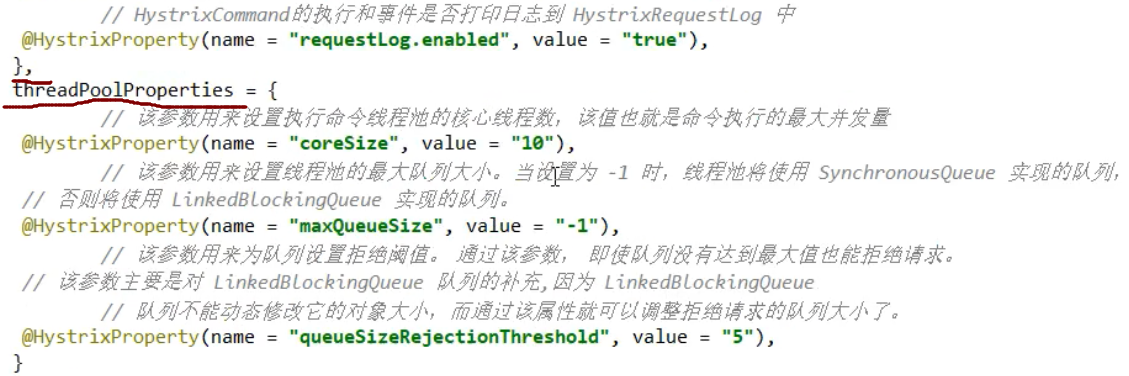
熔断整体流程:
1 | 1请求进来,首先查询缓存,如果缓存有,直接返回 |
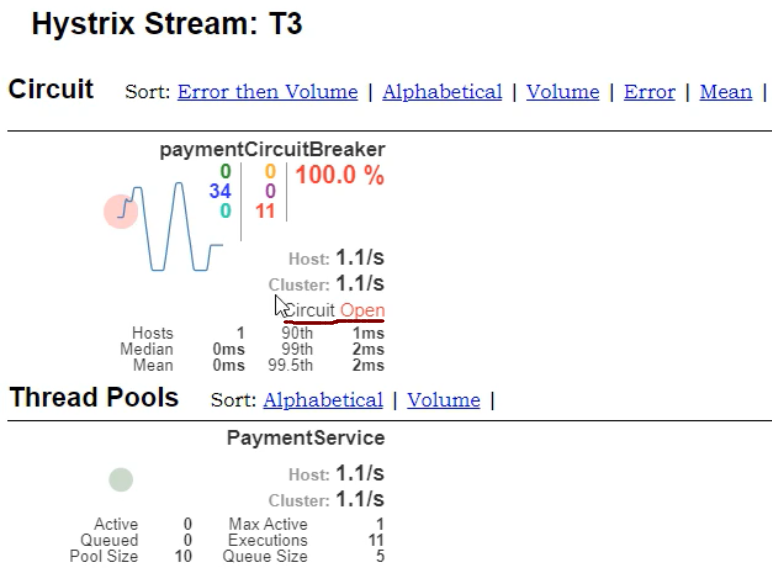
Hystrix服务监控:
HystrixDashboard

2,使用HystrixDashboard:
1,创建项目:
名字: cloud_hystrixdashboard_9001
2,pom文件
3,配置文件
4,主启动类
5,修改所有pay模块(8001,8002,8003…)
他们都添加一个pom依赖:

之前的pom文件中都添加过了,==这个是springboot的监控组件==
6,启动9001即可
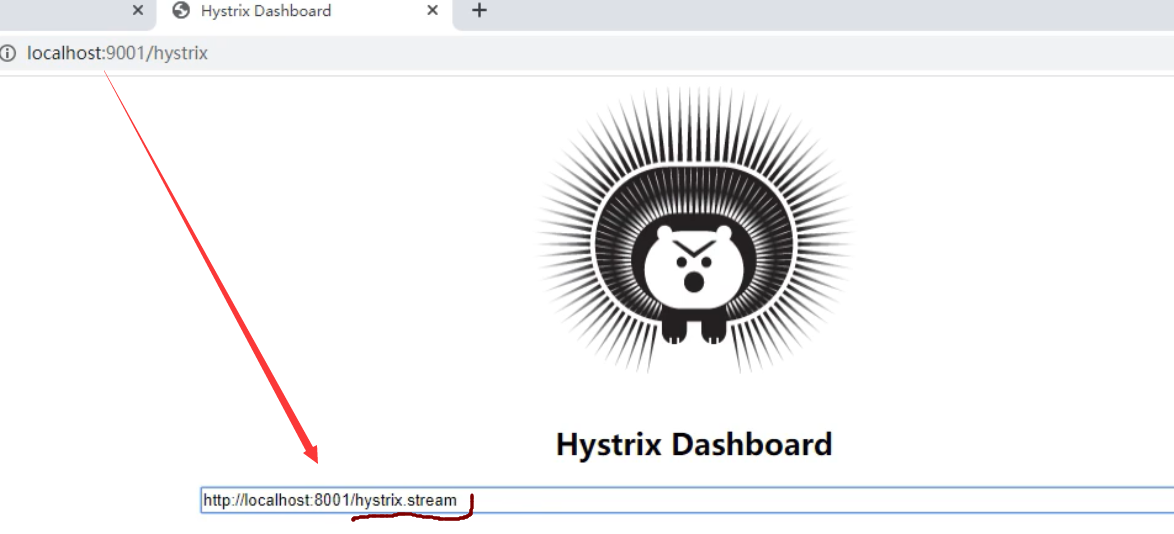
访问: localhost:9001/hystrix
7,注意,此时仅仅是可以访问HystrixDashboard,并不代表已经监控了8001,8002
如果要监控,还需要配置:(8001为例)
==8001的主启动类添加:==
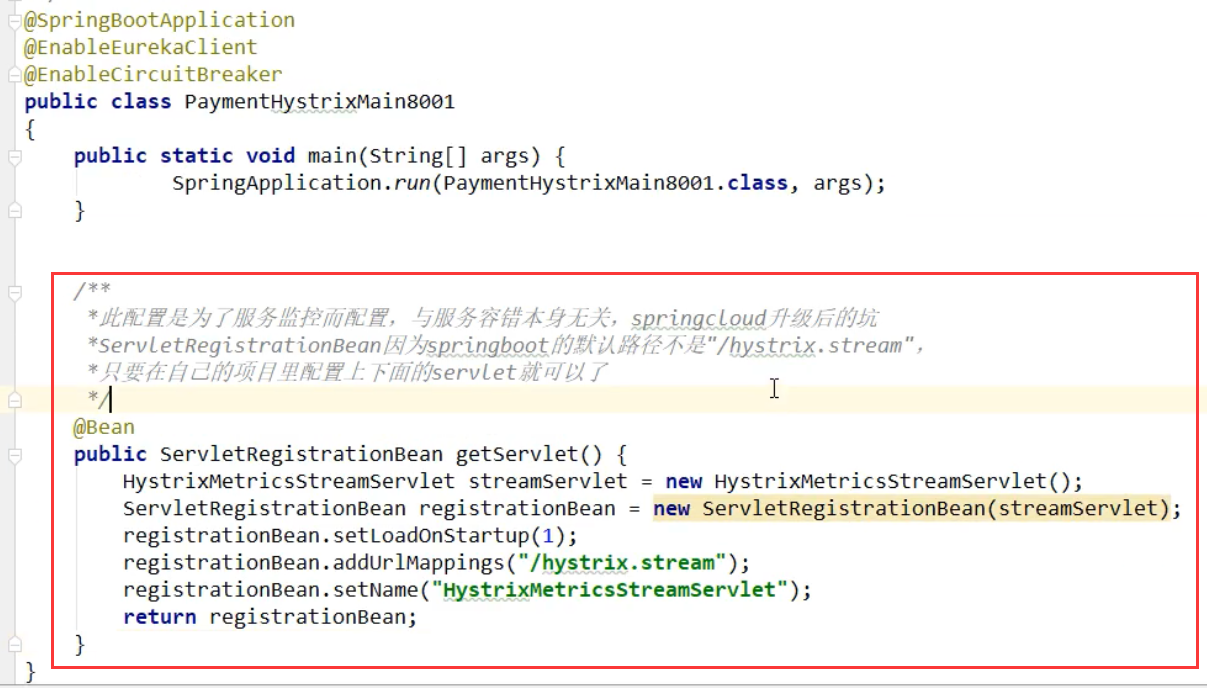
其他8002,8003都是一样的
8,到此,可以启动服务
启动7001,8001,9001
然后在web界面,指定9001要监控8001:



...
...
This is copyright.