前言
本文包含的基本概念包含:Index、Type、Document。集群,节点,分片及副本,倒排索引,分词器。
1.Index,Type,Document
1.1 Index
index:索引是文档(Document)的容器,是一类文档的集合。
索引这个词在 ElasticSearch 会有三种意思:
1)、索引(名词)
类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库(Database)。索引由其名称(必须为全小写字符)进行标识。
2)、索引(动词)
保存一个文档到索引(名词)的过程。这非常类似于SQL语句中的 INSERT关键词。如果该文档已存在时那就相当于数据库的UPDATE。
3)、倒排索引
关系型数据库通过增加一个B+树索引到指定的列上,以便提升数据检索速度。索引ElasticSearch 使用了一个叫做 倒排索引 的结构来达到相同的目的。
1.2 Type
Type 可以理解成关系数据库中Table。
之前的版本中,索引和文档中间还有个类型的概念,每个索引下可以建立多个类型,文档存储时需要指定index和type。从6.0.0开始单个索引中只能有一个类型,
7.0.0以后将将不建议使用,8.0.0 以后完全不支持。
弃用该概念的原因:
我们虽然可以通俗的去理解Index比作 SQL 的 Database,Type比作SQL的Table。但这并不准确,因为如果在SQL中,Table 之前相互独立,同名的字段在两个表中毫无关系。
但是在ES中,同一个Index 下不同的 Type 如果有同名的字段,他们会被 Luecence 当作同一个字段 ,并且他们的定义必须相同。所以我觉得Index现在更像一个表,
而Type字段并没有多少意义。目前Type已经被Deprecated,在7.0开始,一个索引只能建一个Type为_doc
1.3 Document
Document Index 里面单条的记录称为Document(文档)。等同于关系型数据库表中的行。
我们来看下一个文档的源数据
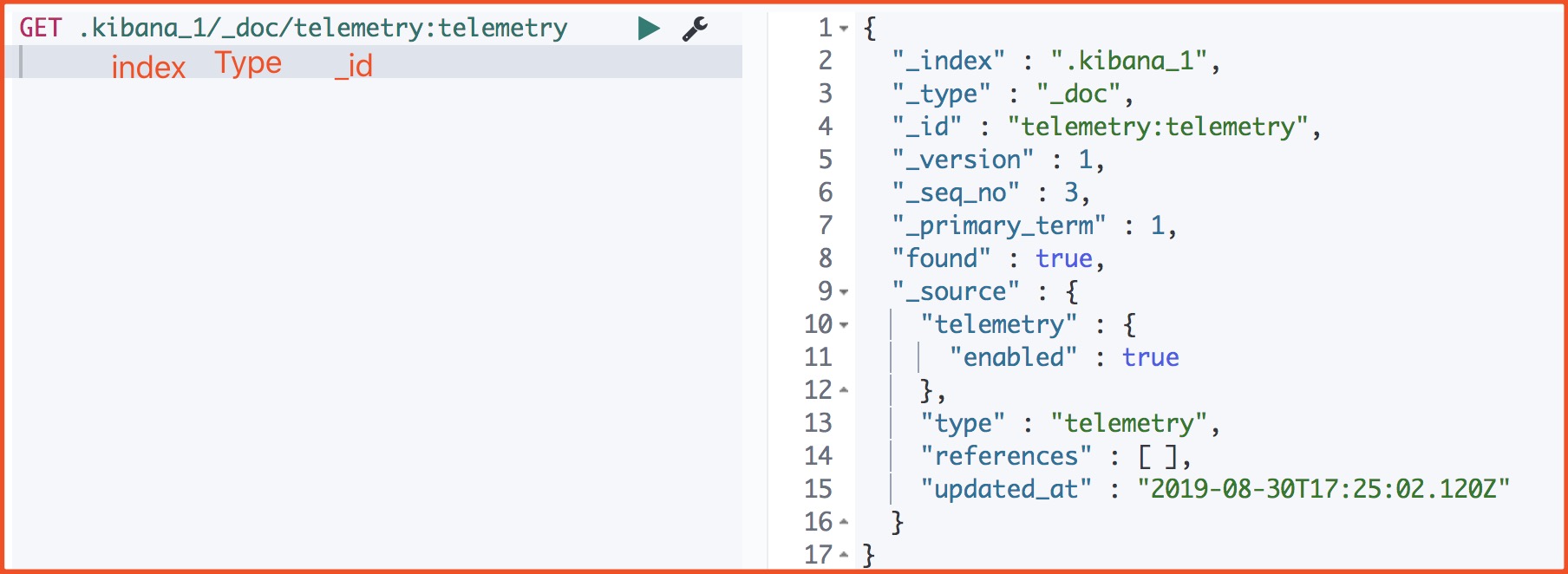
_index 文档所属索引名称。
_type 文档所属类型名。
_id Doc的主键。在写入的时候,可以指定该Doc的ID值,如果不指定,则系统自动生成一个唯一的UUID值。
_version 文档的版本信息。Elasticsearch通过使用version来保证对文档的变更能以正确的顺序执行,避免乱序造成的数据丢失。
_seq_no 严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
primary_term primary_term也和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
found 查询的ID正确那么ture, 如果 Id 不正确,就查不到数据,found字段就是false。
_source 文档的原始JSON数据。
二、集群,节点,分片及副本
2.1、集群
ElasticSearch集群实际上是一个分布式系统,它需要具备两个特性:
1)高可用性
a)服务可用性:允许有节点停止服务;
b)数据可用性:部分节点丢失,不会丢失数据;
2)可扩展性
随着请求量的不断提升,数据量的不断增长,系统可以将数据分布到其他节点,实现水平扩展;
一个集群中可以有一个或者多个节点;
集群健康值
green:所有主要分片和复制分片都可用yellow:所有主要分片可用,但不是所有复制分片都可用red:不是所有的主要分片都可用
当集群状态为 red,它仍然正常提供服务,它会在现有存活分片中执行请求,我们需要尽快修复故障分片,防止查询数据的丢失;
2.2、节点(Node)
1)节点是什么?
a)节点是一个ElasticSearch的实例,其本质就是一个Java进程;
b)一台机器上可以运行多个ElasticSearch实例,但是建议在生产环境中一台机器上只运行一个ElasticSearch实例;
Node 是组成集群的一个单独的服务器,用于存储数据并提供集群的搜索和索引功能。与集群一样,节点也有一个唯一名字,默认在节点启动时会生成一个uuid作为节点名,
该名字也可以手动指定。单个集群可以由任意数量的节点组成。如果只启动了一个节点,则会形成一个单节点的集群。
2、节点(Node)
1)节点是什么?
a)节点是一个ElasticSearch的实例,其本质就是一个Java进程;
b)一台机器上可以运行多个ElasticSearch实例,但是建议在生产环境中一台机器上只运行一个ElasticSearch实例;
Node 是组成集群的一个单独的服务器,用于存储数据并提供集群的搜索和索引功能。与集群一样,节点也有一个唯一名字,默认在节点启动时会生成一个uuid作为节点名,
该名字也可以手动指定。单个集群可以由任意数量的节点组成。如果只启动了一个节点,则会形成一个单节点的集群。
2.3、分片
1 | Primary Shard(主分片) |
ES中的shard用来解决节点的容量上限问题,,通过主分片,可以将数据分布到集群内的所有节点之上。
它们之间关系
1 | 一个节点对应一个ES实例; |
一个索引中的数据保存在多个分片中(默认为一个),相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,
但是应用程序是直接与索引而不是与分片进行交互。
1 | Replica Shard(副本) |
副本有两个重要作用:
1、服务高可用:由于数据只有一份,如果一个node挂了,那存在上面的数据就都丢了,有了replicas,只要不是存储这条数据的node全挂了,数据就不会丢。因此分片副本不会与
主分片分配到同一个节点;
2、扩展性能:通过在所有replicas上并行搜索提高搜索性能.由于replicas上的数据是近实时的(near realtime),因此所有replicas都能提供搜索功能,通过设置合理的replicas
数量可以极高的提高搜索吞吐量
1 | 分片的设定 |
对于生产环境中分片的设定,需要提前做好容量规划,因为主分片数是在索引创建时预先设定的,后续无法修改。
分片数设置过小
导致后续无法增加节点进行水平扩展。
导致分片的数据量太大,数据在重新分配时耗时;
分片数设置过大
影响搜索结果的相关性打分,影响统计结果的准确性;
单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
3.倒排索引
ES的搜索功能是基于lucene,而lucene搜索的基本原理就是倒叙索引,倒序排序的结果跟分词的类型有关。
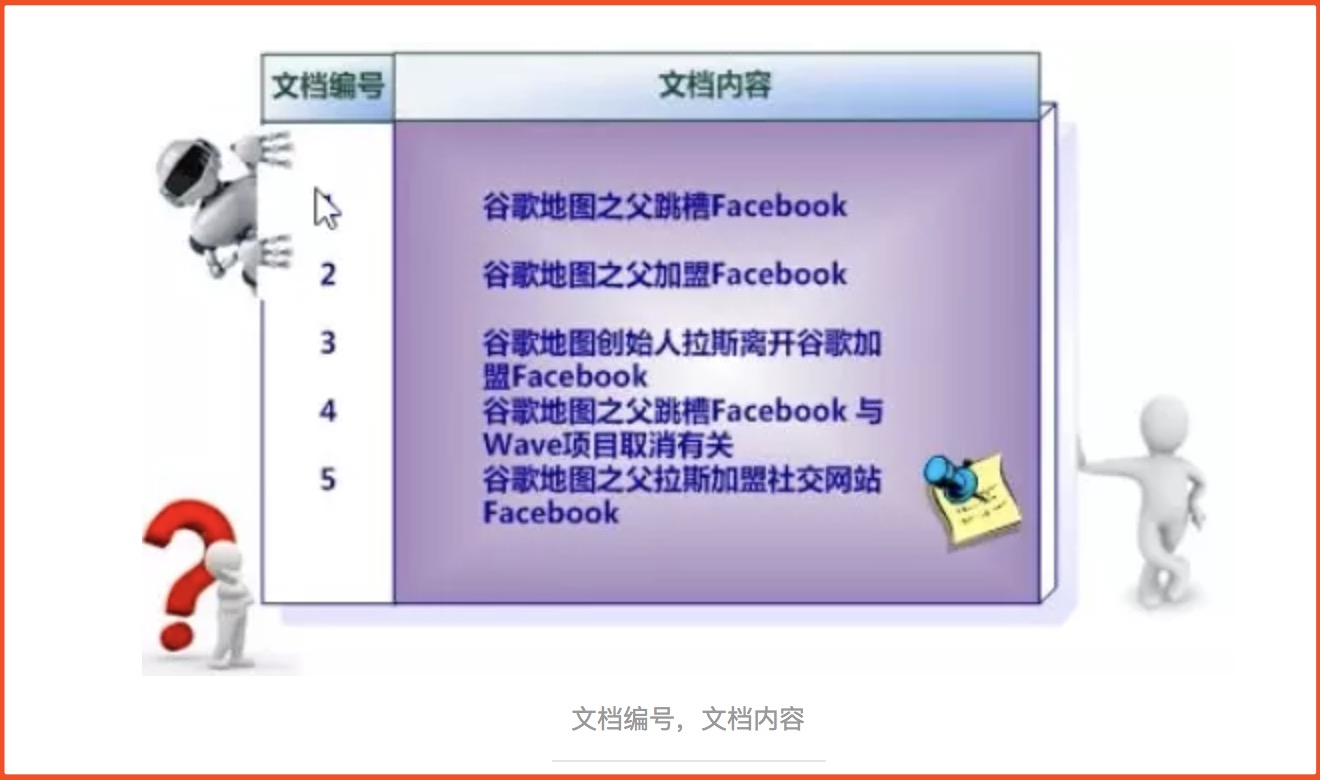
举例
1、假设文档集合包含五个文档,毎个文档内容如图所示,在图中最左端一栏是每个文档对应的文挡编号。
2、首先要用分词系统将文挡自动切分成单词序列,记录下哪些文挡包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
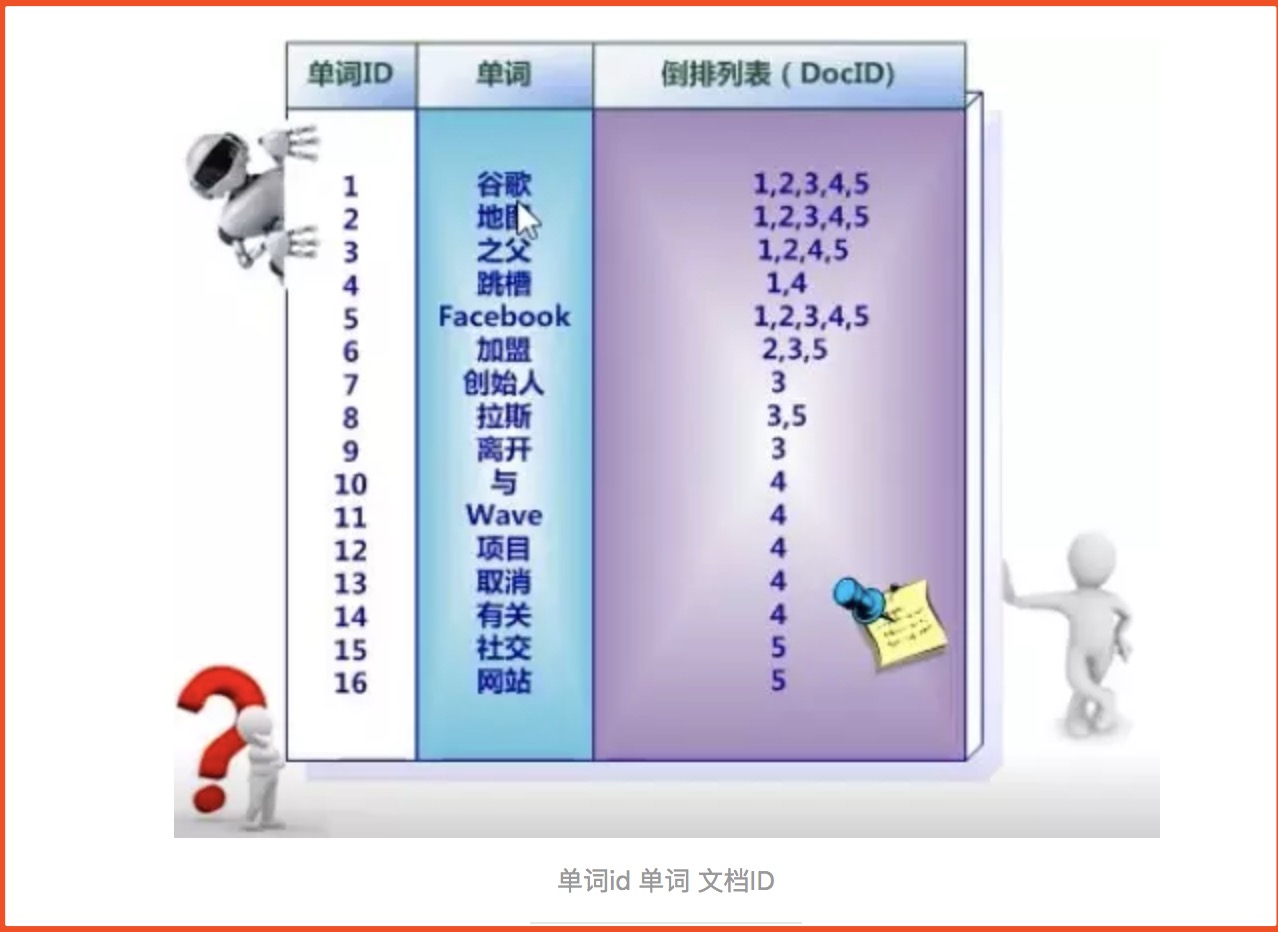
3、索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息。文档中的句子被划分为一个个term(term 用来表示一个单词或词语,取决于使用的分词方式),
倒叙索引中存储着term,term的出现频率(tf,term frequency)和出现位置(倒叙索引中的单词是按顺序排列的,这张图没有体现出来),请注意这里的文档内容是document
中的一个字段,也就是说每个被索引了的字段都有自己的倒叙索引
一次简单的搜索流程
假设我们搜索谷歌地图之父,搜索流程会是这样
- 分词,分词插件将句子分为3个term
谷歌,地图,之父 - 将这3个term拿到倒叙索引中去查找(会很高效,比如二分查找),如果匹配到了就拿对应的文档id,获得文档内容
但是,如何确定结果顺序?
这里要引入_score的概念,对于term的匹配,lucene会对其打分,得分越高,排名越靠前.这里要介绍几个相关的概念
- TF(term frequency),词频,term在当前document中出现的频率,一个term在当前document中出现5次要比出现1次更相关,打分也会更高 - IDF(inverse doucment frequency),逆向文档频率,term在所有document中出现的频率,这个频率越高,该term对应的分值越低 - 字段长度归一值,简单来说就是字段越短,字段的权重越高, 比如 term 我在匹配 我123和我123456时,我123的得分会更高.
4.分词器
4.1分词器概念
4.1.1、Analysis 和 Analyzer
Analysis: 文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词。Analysis是通过Analyzer来实现的。
当一个文档被索引时,每个Field都可能会创建一个倒排索引(Mapping可以设置不索引该Field)。
倒排索引的过程就是将文档通过Analyzer分成一个一个的Term,每一个Term都指向包含这个Term的文档集合。
当查询query时,Elasticsearch会根据搜索类型决定是否对query进行analyze,然后和倒排索引中的term进行相关性查询,匹配相应的文档。
4.1.2 、Analyzer组成
分析器(analyzer)都由三种构件块组成的:character filters , tokenizers , token filters。
1) character filter 字符过滤器
* 在一段文本进行分词之前,先进行预处理,比如说最常见的就是,过滤html标签(hello —> hello),& —> and(I&you —> I and you
2) tokenizers 分词器
英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
3) Token filters Token过滤器
将切分的单词进行加工。大小写转换(例将“Quick”转为小写),去掉词(例如停用词像“a”、“and”、“the”等等),或者增加词(例如同义词像“jump”和“leap”)。
三者顺序:Character Filters—->Tokenizer—->Token Filter
三者个数:analyzer = CharFilters(0个或多个) + Tokenizer(恰好一个) + TokenFilters(0个或多个)
4.1.3、Elasticsearch的内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
4.1.4、创建索引时设置分词器
1 | PUT new_index |
4.2 ES内置分词器
这里讲解下常见的几个分词器:Standard Analyzer、Simple Analyzer、whitespace Analyzer。
4.2.1、Standard Analyzer(默认)
1)示例
standard 是默认的分析器。它提供了基于语法的标记化(基于Unicode文本分割算法),适用于大多数语言
1 | POST _analyze |
运行结果
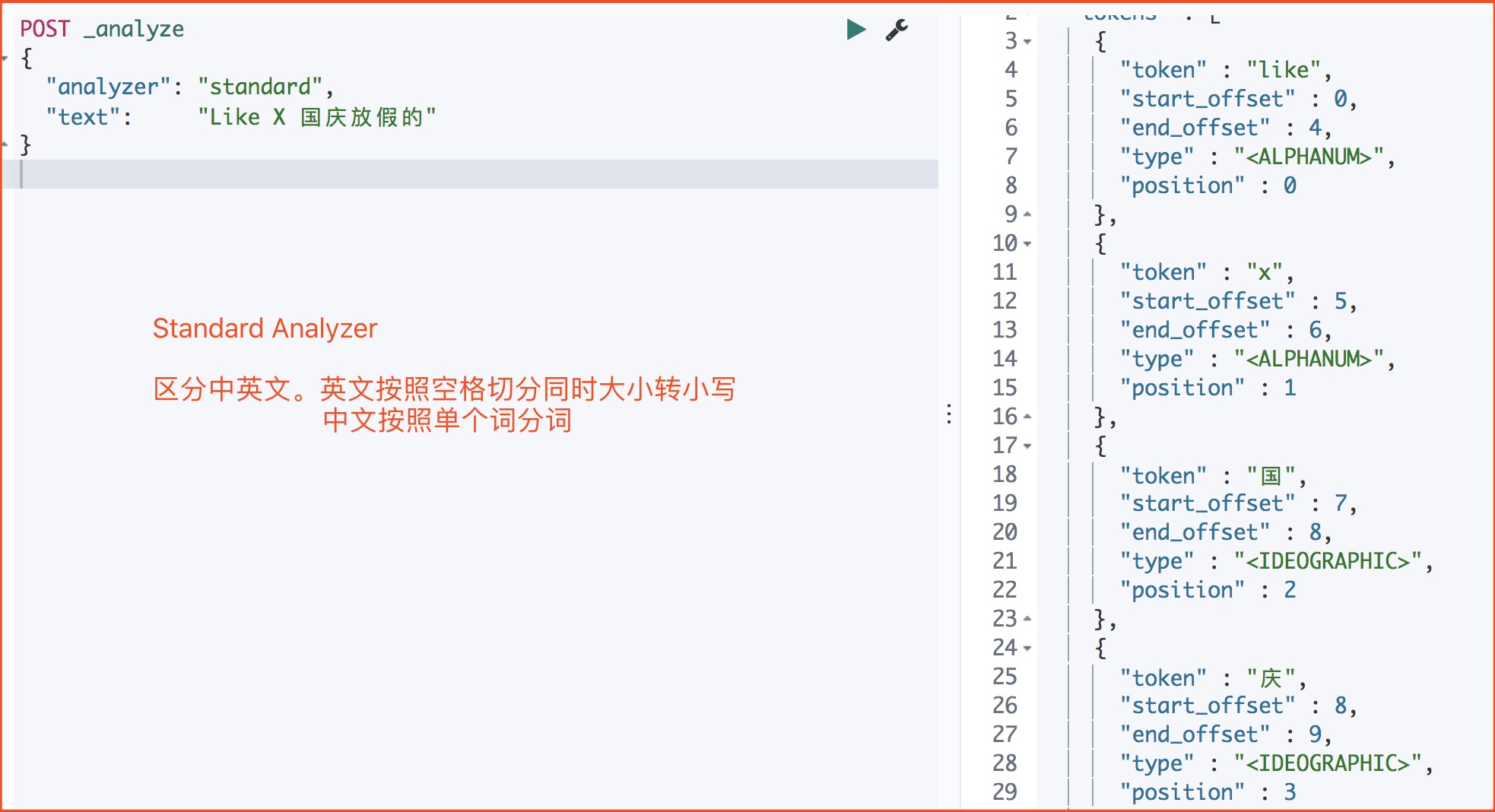
2)配置
标准分析器接受下列参数:
- max_token_length : 最大token长度,默认255
- stopwords : 预定义的停止词列表,如
_english_或 包含停止词列表的数组,默认是_none_ - stopwords_path : 包含停止词的文件路径
1 | PUT new_index |
4.2.2 Simple Analyzer
simple 分析器当它遇到只要不是字母的字符,就将文本解析成term,而且所有的term都是小写的。
1 | POST _analyze |
运行结果
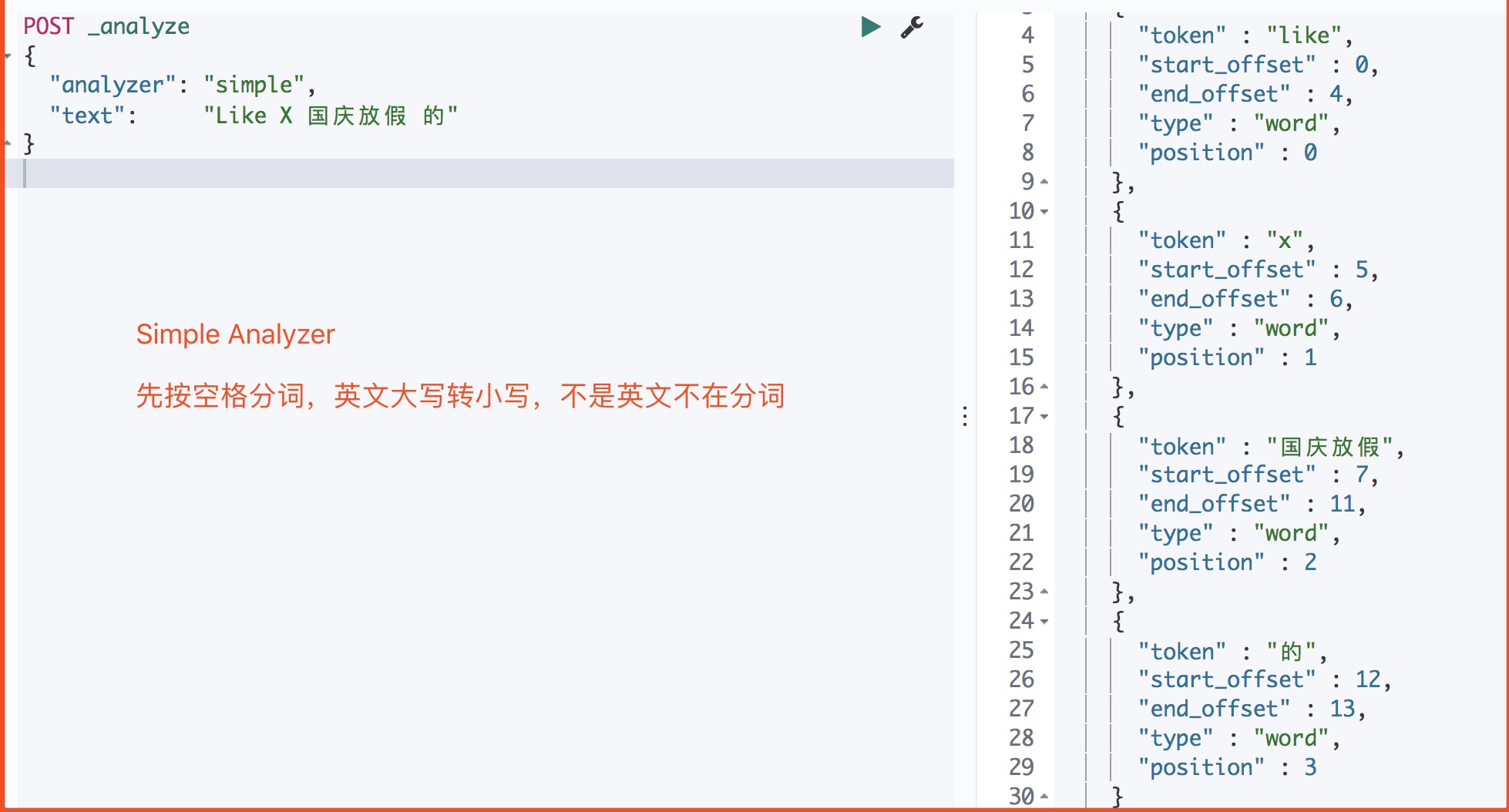
4.2.3、Whitespace Analyzer
1 | POST _analyze |
返回
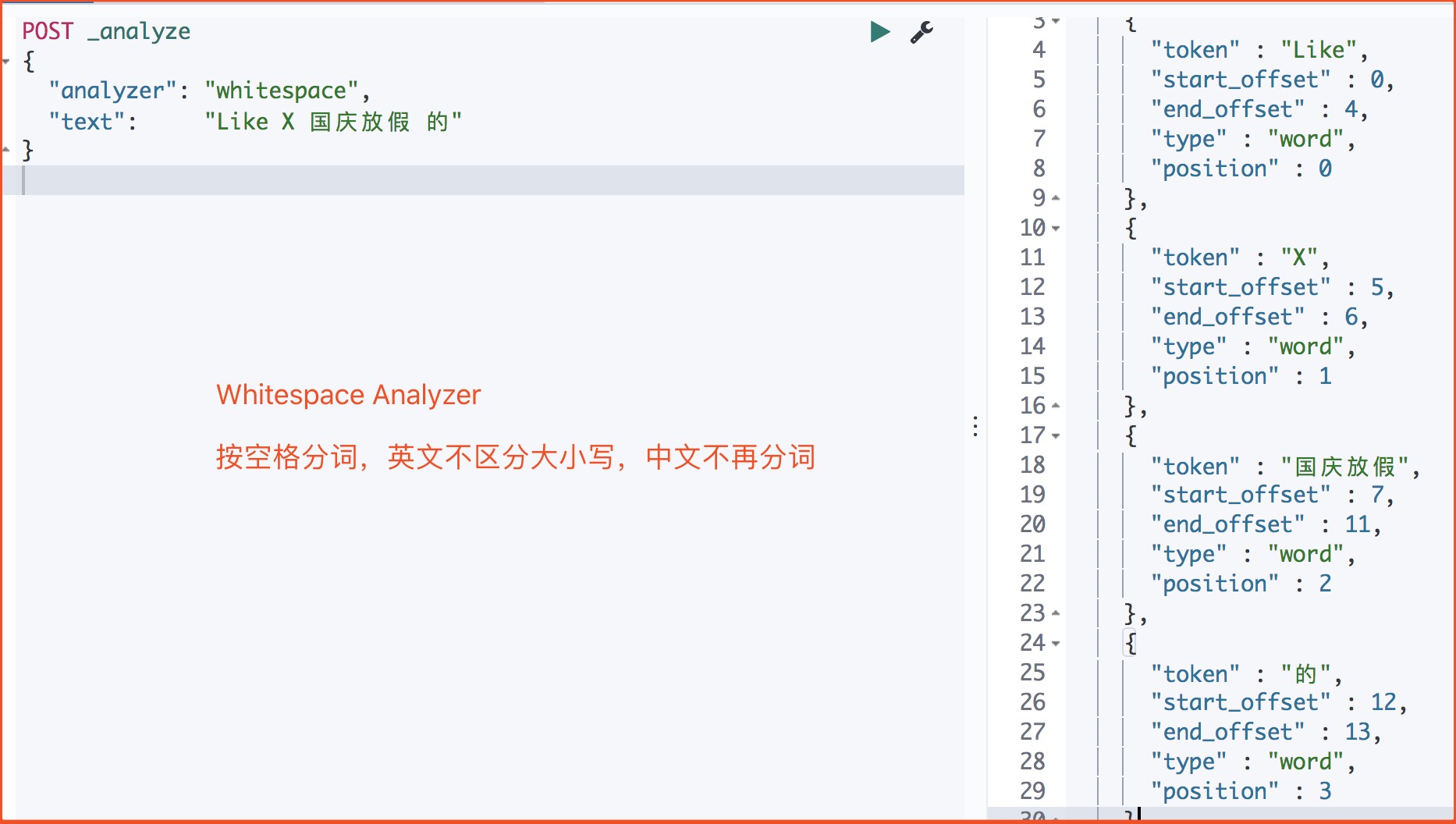
4.3中文分词器
中文的分词器现在大家比较推荐的就是 IK分词器,当然也有些其它的比如 smartCN、HanLP。
这里只讲如何使用IK做为中文分词。
1、IK分词器安装
开源分词器 Ik 的github:https://github.com/medcl/elasticsearch-analysis-ik
注意 IK分词器的版本要你安装ES的版本一致,我这边是7.1.0那么就在github找到对应版本,然后启动命令··
1 | ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.1.0/elasticsearch-analysis-ik-7.1.0.zip |
运行结果

注意 安装完插件后需重启Es,才能生效。
2、IK使用
IK有两种颗粒度的拆分:
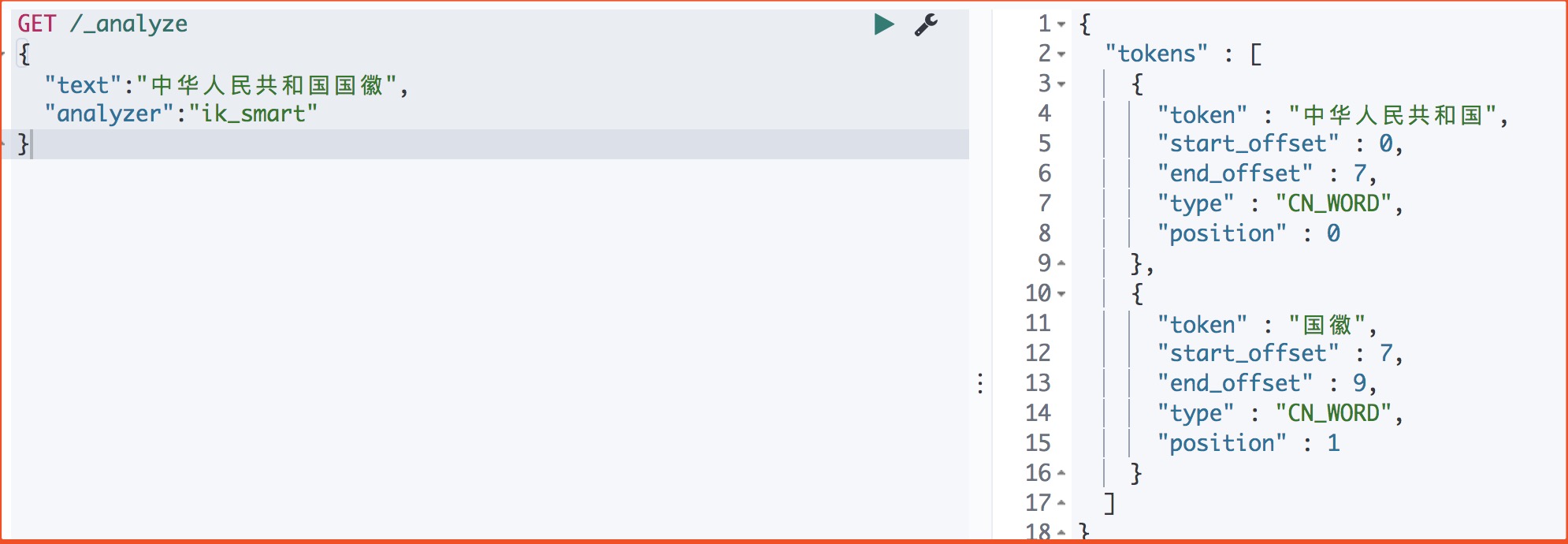
ik_smart: 会做最粗粒度的拆分
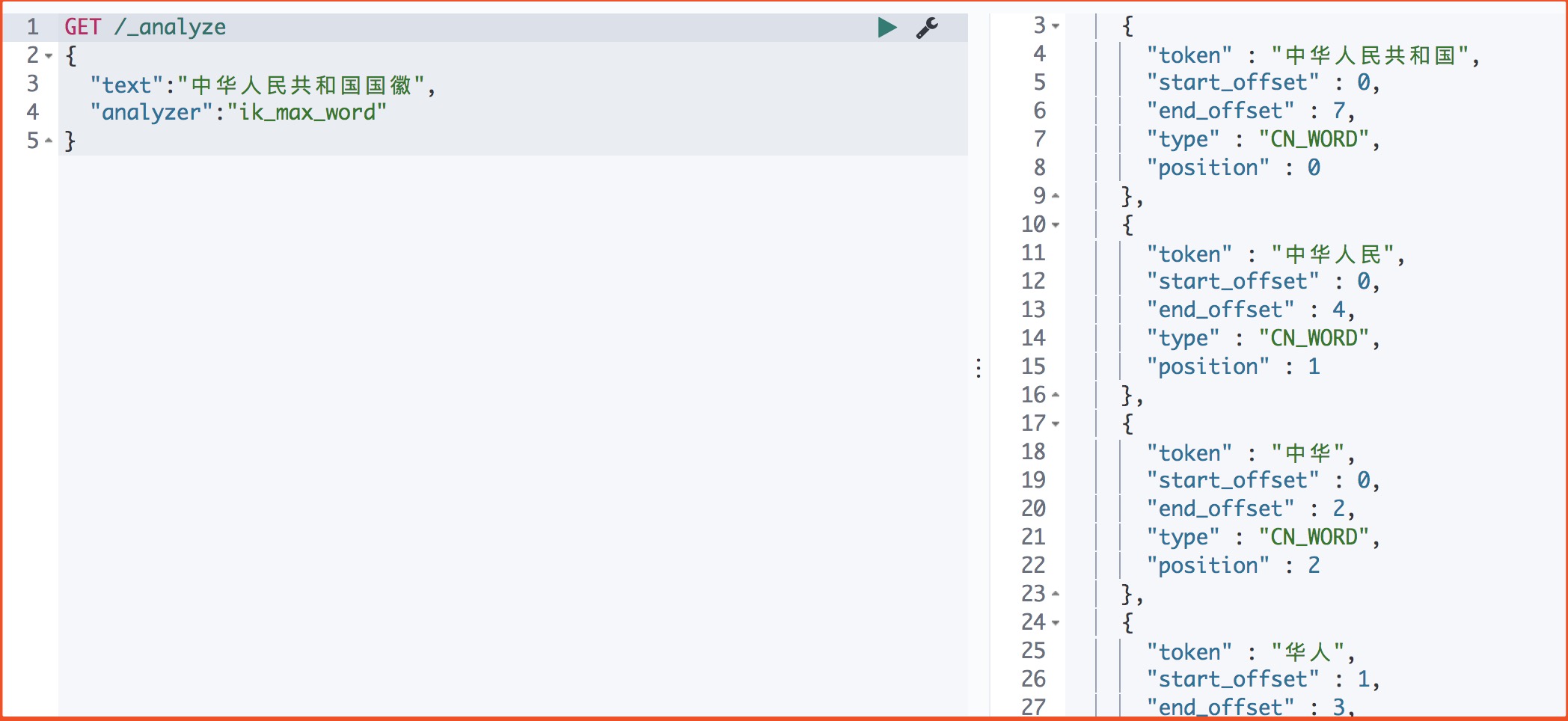
ik_max_word: 会将文本做最细粒度的拆分
1) ik_smart 拆分
1 | GET /_analyze |
运行结果
2)ik_max_word 拆分
1 | GET /_analyze |
运行结果

Canon
Brooklyn Duo
This is copyright.