前言
在Mysql中,我们可以获取一组数据的 最大值(Max)、最小值(Min)。同样我们能够对这组数据进行 分组(Group)。那么对于Elasticsearch中
我们也可以实现同样的功能,聚合有关资料官方文档内容较多,这里大概分两篇博客写这个有关Elasticsearch聚合。
官方对聚合有四个关键字: Metric(指标)、Bucketing(桶)、Matrix(矩阵)、Pipeline(管道)。
概念
1. ES聚合分析是什么?
概念 Elasticsearch除全文检索功能外提供的针对Elasticsearch数据做统计分析的功能。它的实时性高,所有的计算结果都是即时返回。
Elasticsearch将聚合分析主要分为如下4类:
1 | Metric(指标): 指标分析类型,如计算最大值、最小值、平均值等等 (对桶内的文档进行聚合分析的操作) |
2.ES聚合分析查询的写法
在查询请求体中以aggregations节点按如下语法定义聚合分析:
1 | "aggregations" : { |
说明:aggregations 也可简写为 aggs
3、指标(metric)和 桶(bucket)
虽然Elasticsearch有四种聚合方式,但在一般实际开发中,用到的比较多的就是Metric和Bucket。
(1) 桶(bucket)
a、简单来说桶就是满足特定条件的文档的集合。
b、当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件,如果匹配到,文档将放入相应的桶并接着开始聚合操作。
c、桶也可以被嵌套在其他桶里面。
(2)指标(metric)
a、桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的地的手段:它提供了一种给文档分组的方法来让
我们可以计算感兴趣的指标。
b、大多数指标是简单的数学运算(如:最小值、平均值、最大值、汇总),这些是通过文档的值来计算的。
1 | } |
返回结果
1 | { |
结果说明:时间小于500的文档占比为55.1%,时间小于600的文档占比为64%,
9、Top Hits
一般用于分桶后获取该桶内匹配前n的文档列表
1 | POST /sales/_search?size=0 |
三、示例
下面会针对上面官方文档的例子进行举例说明。
1、添加测试数据
1)创建索引
1 | DELETE /employees |
2)添加数据
添加10条数据,每条数据包含:姓名、年龄、工作、性别、薪资
1 | PUT /employees/_bulk |
2、求薪资最低值
1 | POST employees/_search |
返回
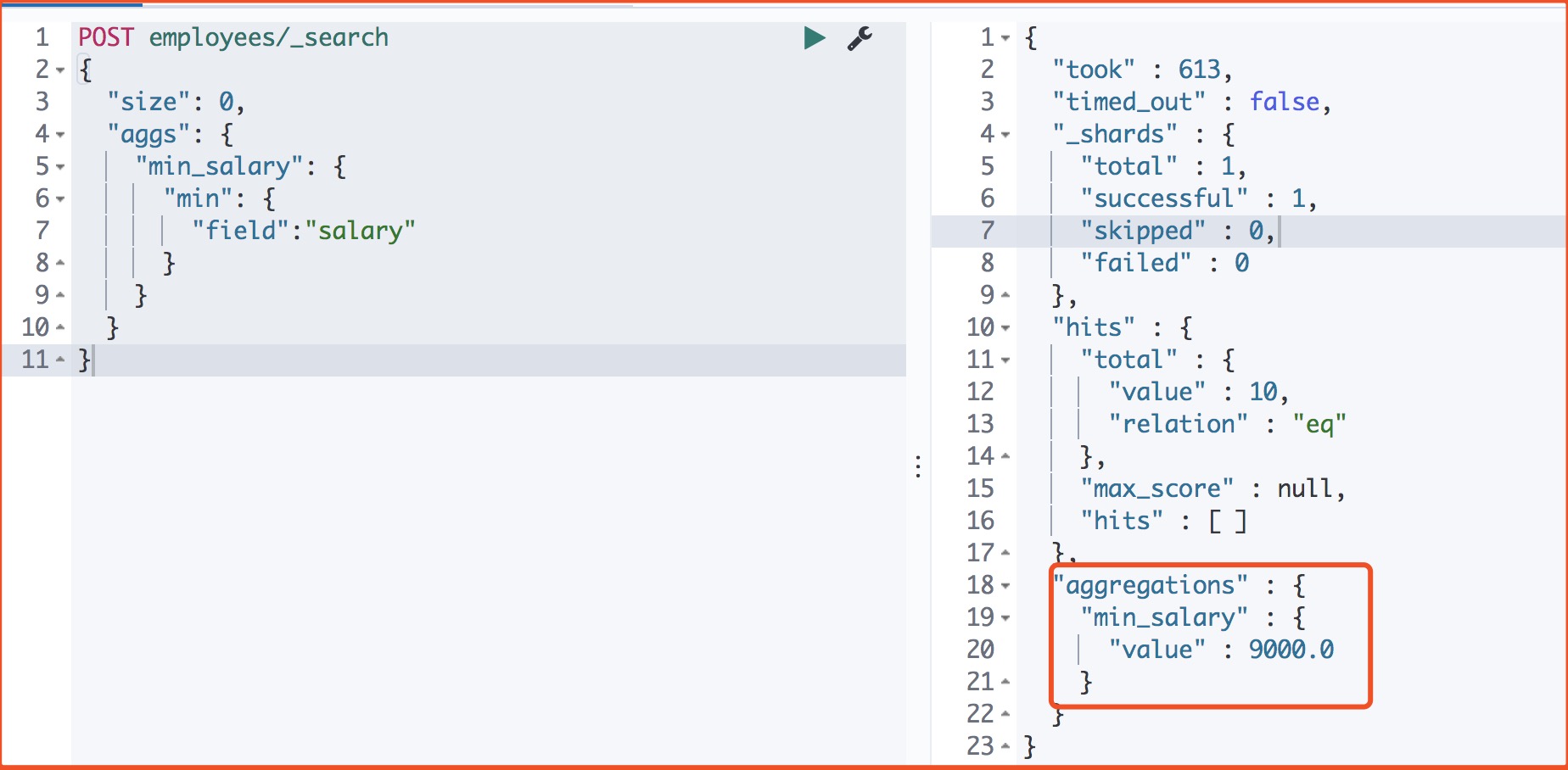
3、找到最低、最高和平均工资
1 | POST employees/_search |
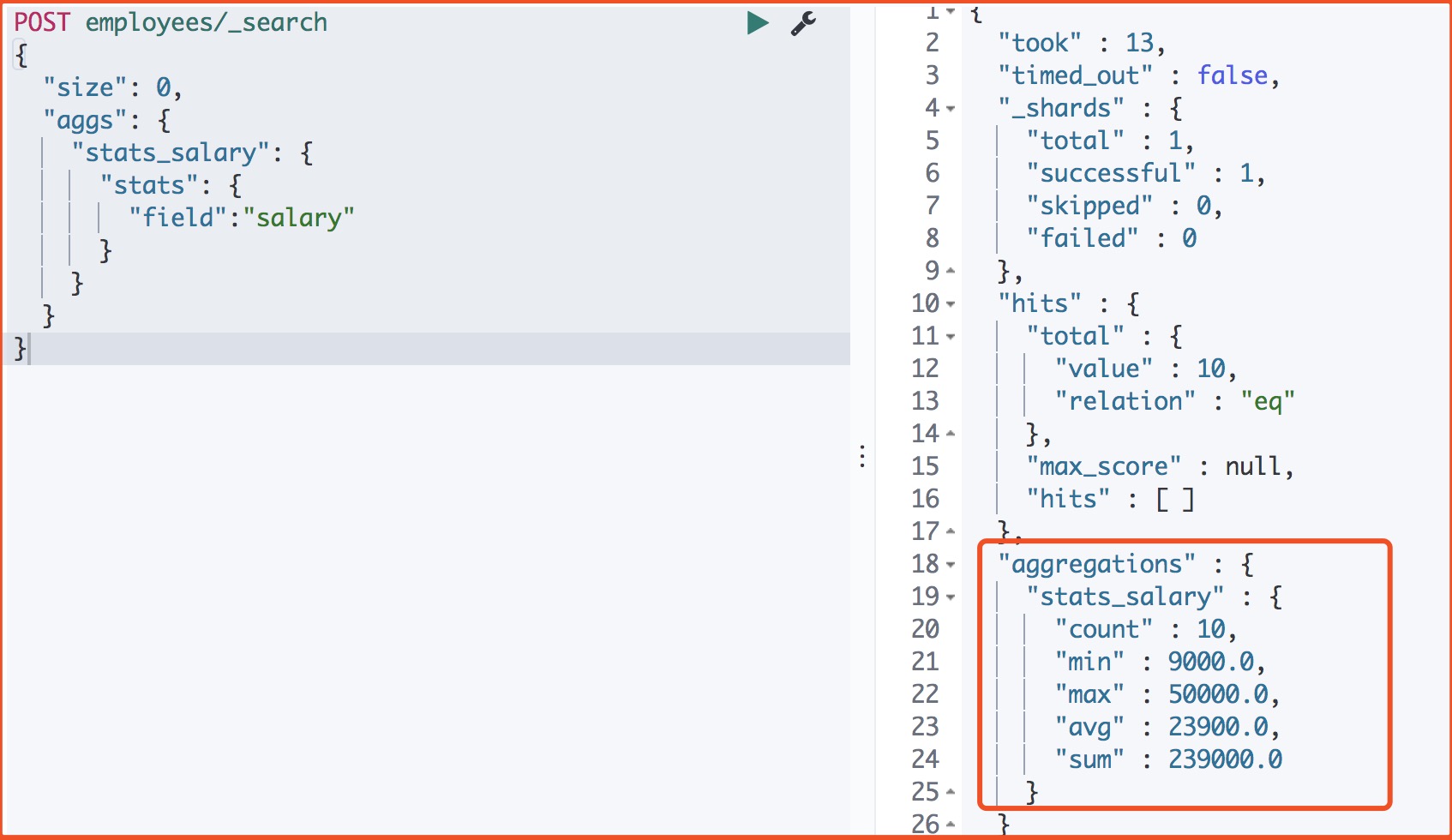
4、一个聚合,输出多值
1 | POST employees/_search |
返回
5、求一共有多少工作类型
1 | POST employees/_search |
返回
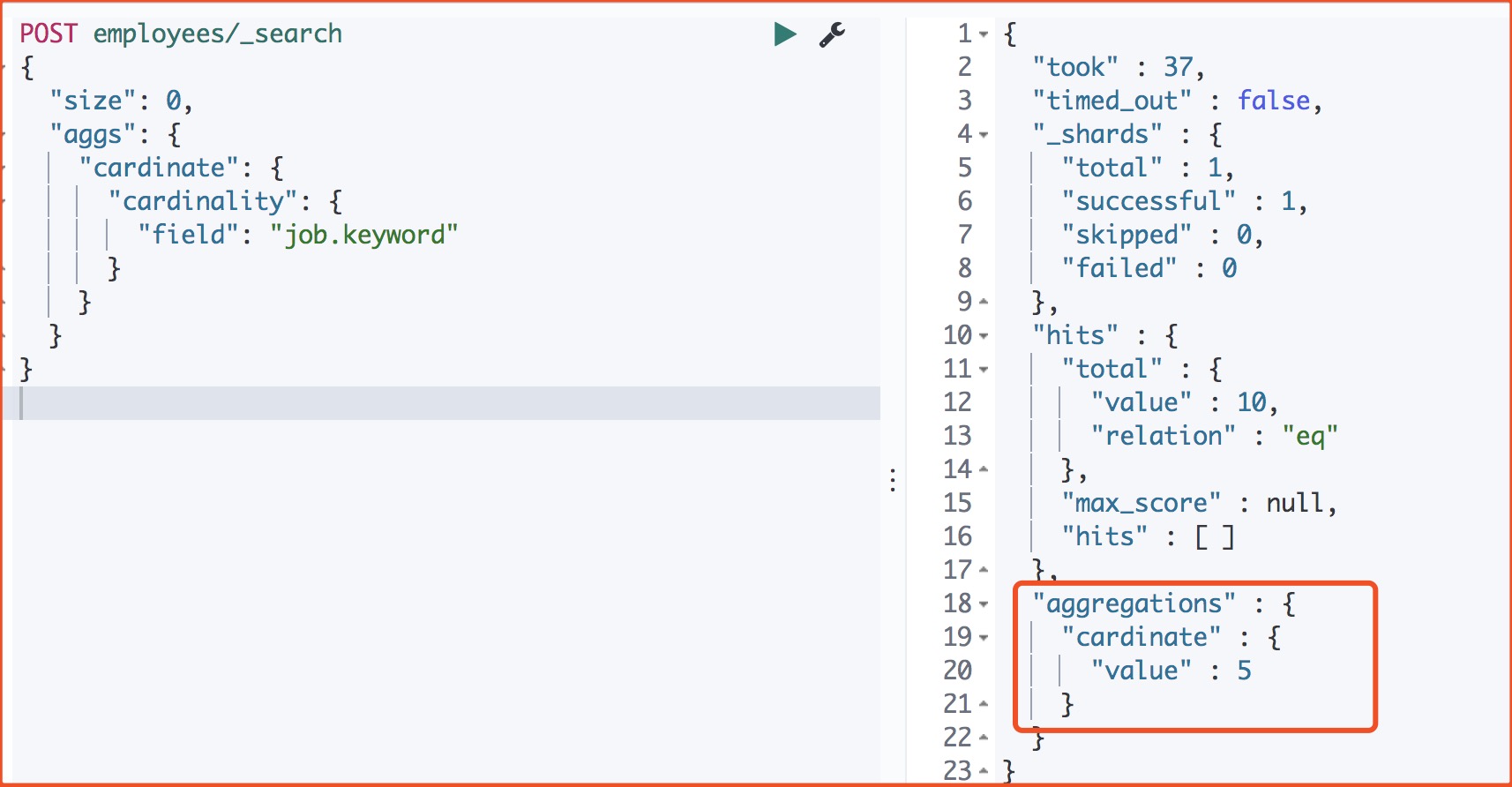
注意 我们需要把job的类型为keyword类型,这样就不会分词,把它当成一个整体。
6、查看中位数的薪资
1 | POST employees/_search |
返回
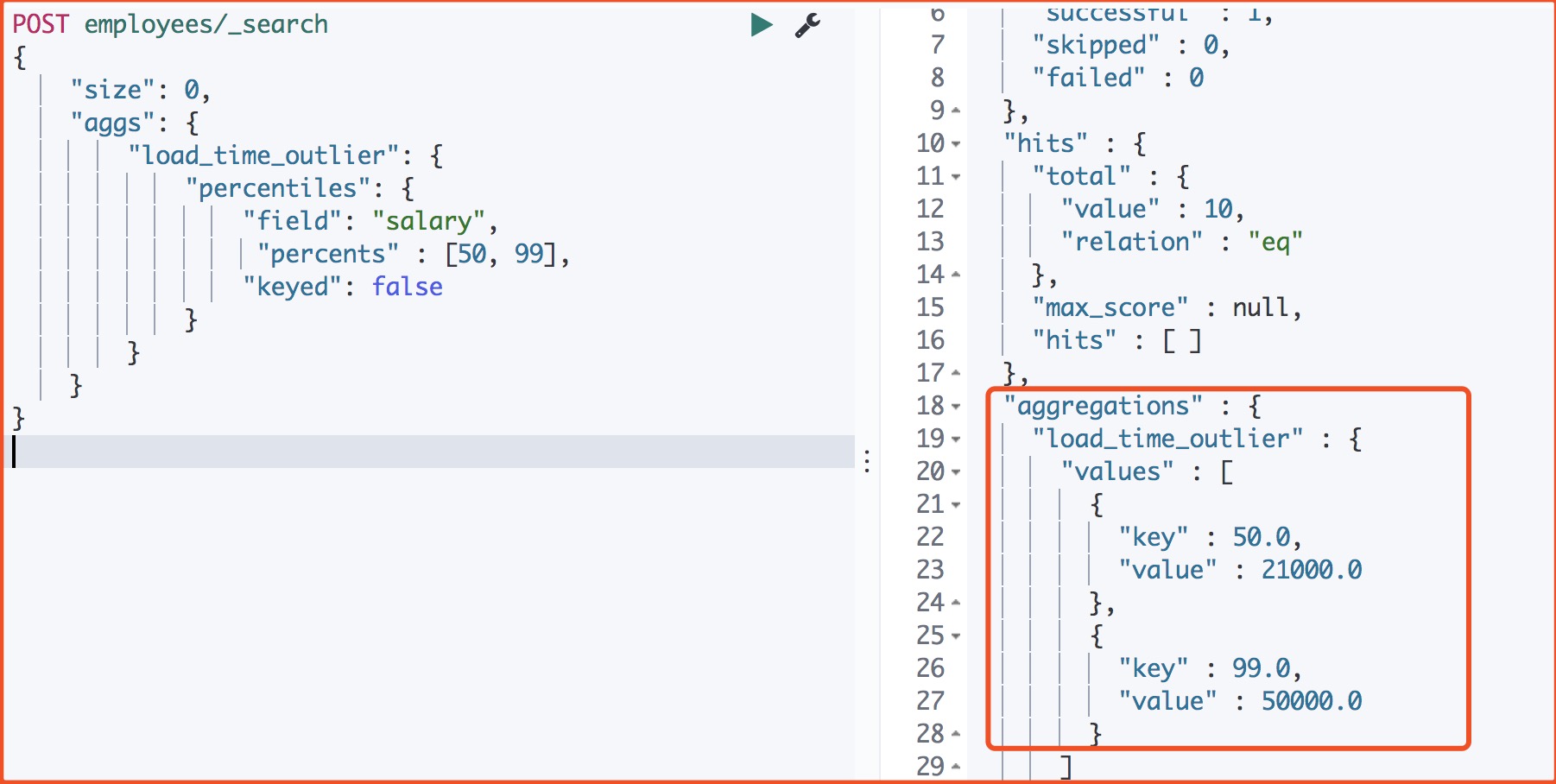
发现这些工作的中位数是:21000元。
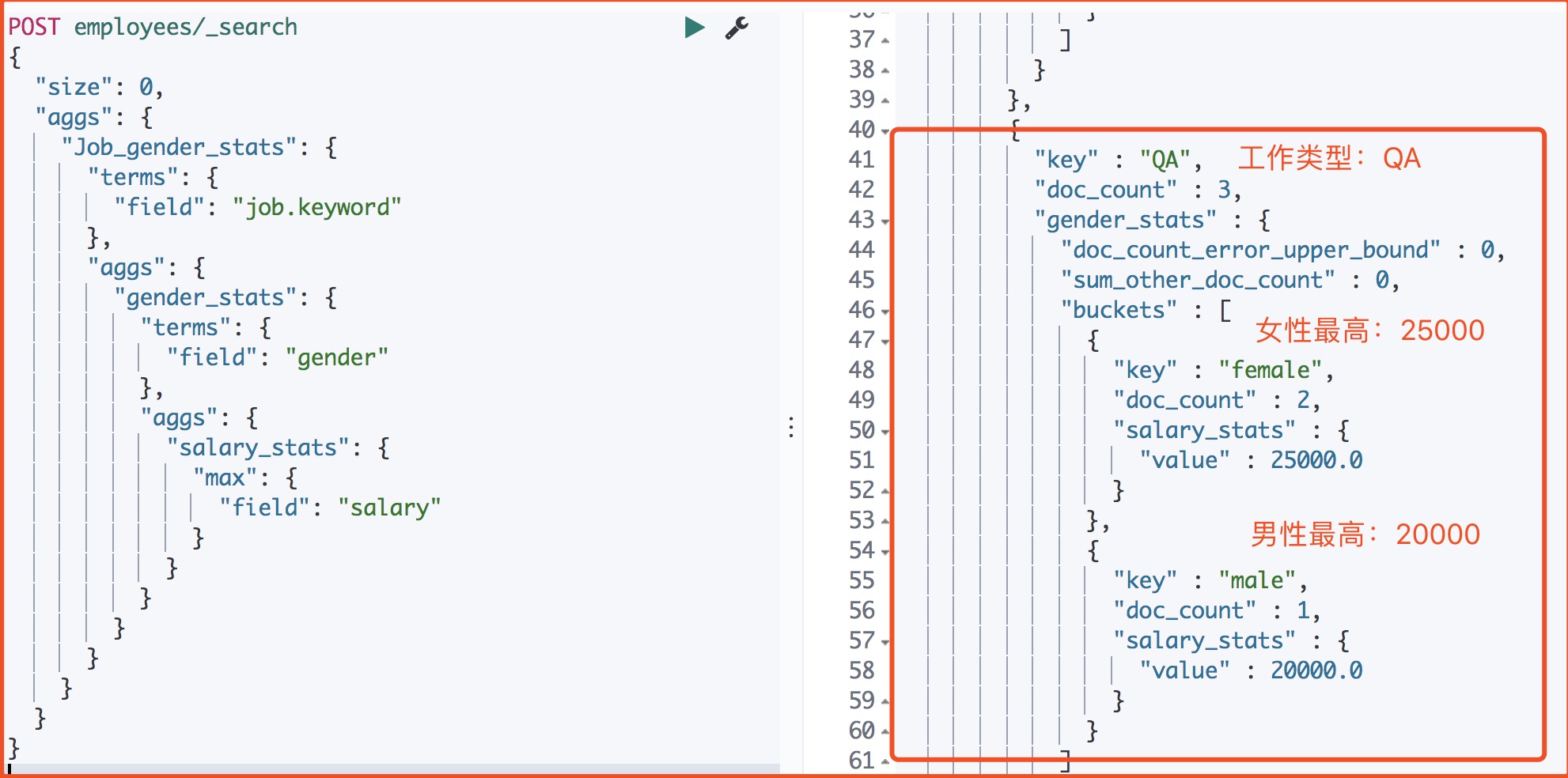
7、取每个工作类型薪资最高的数据
多层嵌套 根据工作类型分桶,然后按照性别分桶,计算每个桶中工资的最高的薪资。
1 | POST employees/_search |
返回
...
...
This is copyright.