前言
复合查询有:bool query(布尔查询)、boosting query(提高查询)、constant_score(固定分数查询)、dis_max(最佳匹配查询)、function_score(函数查询)。
一、bool query(布尔查询)
1、概念
定义 可以理解成通过布尔逻辑将较小的查询组合成较大的查询。
Bool查询语法有以下特点
- 子查询可以任意顺序出现
- 可以嵌套多个查询,包括bool查询
- 如果bool查询中没有must条件,should中必须至少满足一条才会返回结果。
bool查询包含四种操作符,分别是must,should,must_not,filter。他们均是一种数组,数组里面是对应的判断条件。
1 | must: 必须匹配。贡献算分 |
2、官方例子
看下官方举例
1 | POST _search |
在filter元素下指定的查询对评分没有影响 , 评分返回为0。分数仅受已指定查询的影响。
1 | 官方例子 |
这个例子查询查询为所有文档分配0分,因为没有指定评分查询。
1 | 官方例子 |
此bool查询具有match_all查询,该查询为所有文档指定1.0分。
3、Bool嵌套查询
1 | # 嵌套,实现了 should not 逻辑 |
二、boosting query
1、概念
在上面的复合查询我们可以通过must_not+must 先剔除不想匹配的文档,再获取匹配的文档,但是有一种场景就是我并不需要完全剔除,而是把需要剔除的那部分文档的
分数降低。这个时候就可以使用boosting query。下面会举例说明。
2、举例
1)、创建索引并添加数据
1 | # 创建索引并添加数据 |
2)、 bool must复合查询
1 | #查询结果3->1->2 |
3)、bool must_not复合查询
我们需要的是文档中需要包含 apple,但是文档中不包含 pie,那么我们可以这么做
1 | #must_not的方式,将3的记录强制排除掉 (结果 1->2) |
3)、 boosting query
上面第二种比较粗暴,可能我实际开发过程中,如果出现 pie,我并不想把这条记录完全过滤掉,而是希望降低他的分数,让它也出现在列表中,只是查询结果可能比较靠后。
1 | # 通过Boosting的方式,将3的记录也纳入结果集,只是排名会靠后。(结果 1->2->3) |
只有匹配了 positive查询 的文档才会被包含到结果集中,但是同时匹配了negative查询 的文档会被降低其相关度,通过将文档原本的_score和negative_boost参数进行
相乘来得到新的_score。因此,negative_boost参数一般小于1.0。在上面的例子中,任何包含了指定负面词条的文档的_score都会是其原本_score的一半。
3、思考boosting query应用场景
场景举例 我们通过去索引中搜索 ‘苹果公司’ 相关的信息,然后我们在查询中的信息为 ‘苹果’。
1)那么我们查询的条件是:must = ‘苹果’。也就是文档中必须包含’苹果’
但是我们需要的结果是苹果公司相关信息,如果你的文档是 ‘苹果树’,’苹果水果’,那么其实此苹果非彼苹果如果匹配到其实没有任何意义。
2)那么我们修改查询条件为: must = ‘苹果’ AND must_not = ‘树 or 水果’
就是说就算文档包含了苹果,但因为包含了树或者水果那么我们也会过滤这条文档信息,因为我们要查的苹果公司相关信息,如果你是苹果树那对我来讲确实是不匹配,
所以直接过滤掉,看是没啥问题。
但是你想,这样做是不是太粗暴了,因为一个文档中包含’苹果’和’树’那不代表一定是苹果树,而可能是 ‘苹果公司组织员工一起去种树’ 那么这条文档理应出现
而不是直接过滤掉,所以我们就可以用boosting query。就像上面这个例子一样。
三、constant_score(固定分数查询)
定义 常量分值查询,目的就是返回指定的score,一般都结合filter使用,因为filter context忽略score。
1 | 举例 |
运行结果
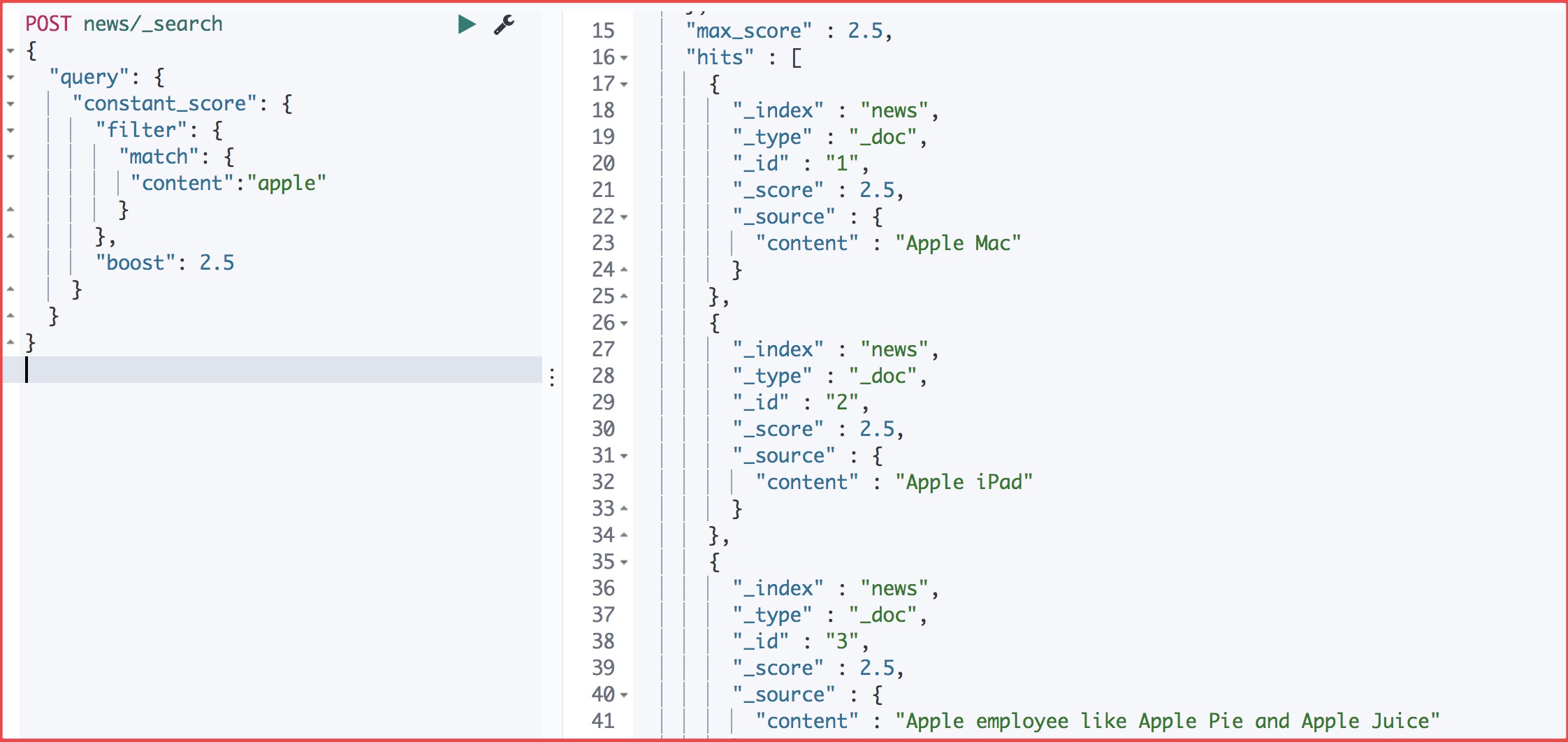
可以看出分数都是2.5
四、dis_max(最佳匹配查询)
1、概念
dis_max : 只是取分数最高的那个query的分数而已。
看下官方例子
1 | GET /_search |
假设一条文档的’title’查询得分是 1,’body’查询得分是1.6。那么总得分为:1.6+1*0.7 = 2.3。
如果我们去掉"tie_breaker" : 0.7 ,那么tie_breaker默认为0,那么这条文档的得分就是 1.6 + 1*0 = 1.6
2、举例
1)创建数据
1 | #1、创建索引 |
2)、should查询
1 | #should查询查询 (结果 3->2->1 |
运行结果
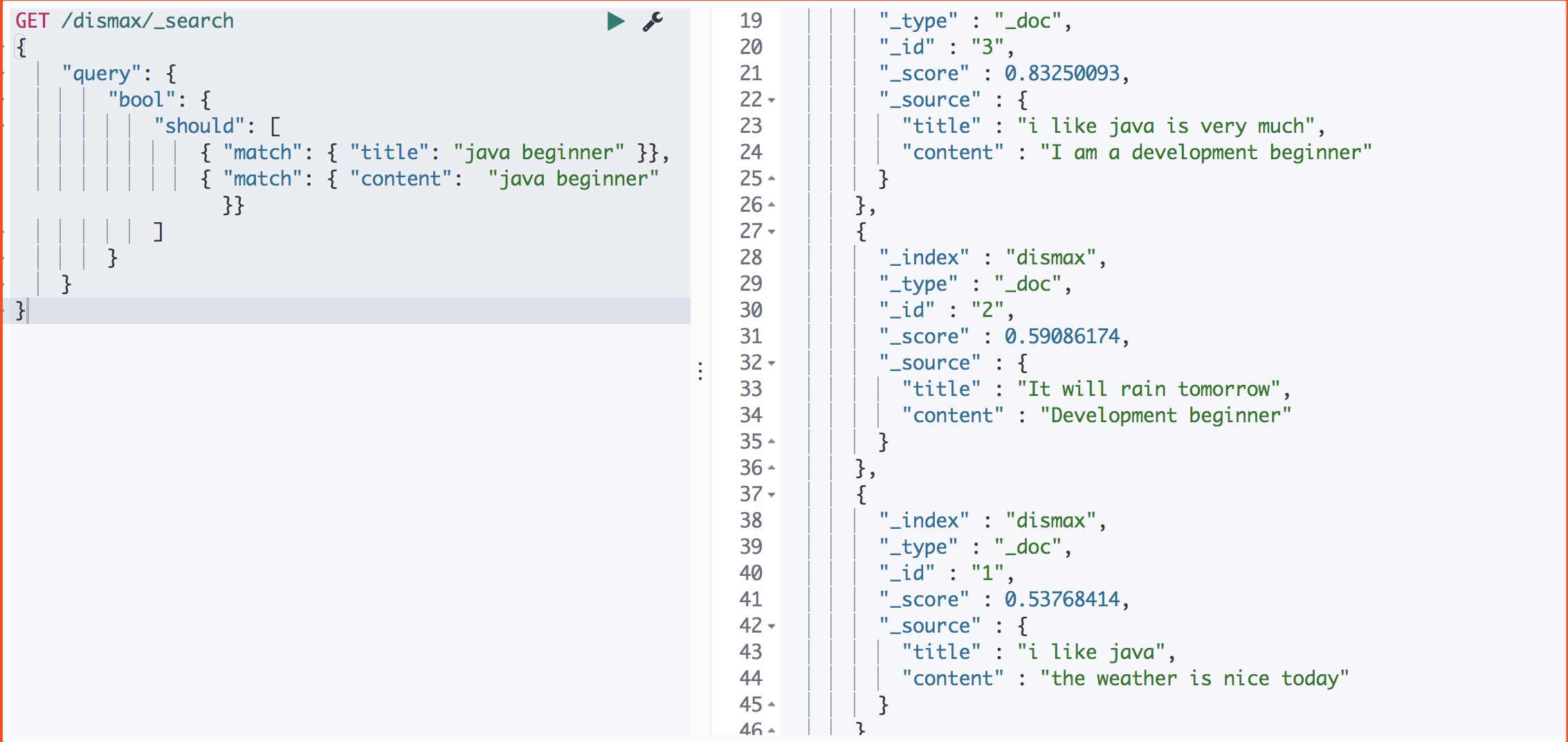
should计算分值:1)、运行should子句中的两个查询 2)、相加查询返回的分值
doc1:title: 0.53 + content: 0 = 0.53
doc2:title:0 + content:0.59 = 0,59
doc3:title:0.41 + content:0.42 = 0.83
所有最终运行结果: 3 – 2 – 1
2)dis_max查询(不带tie_breaker)
1 | #运行结果(2-1-3) |
运行结果
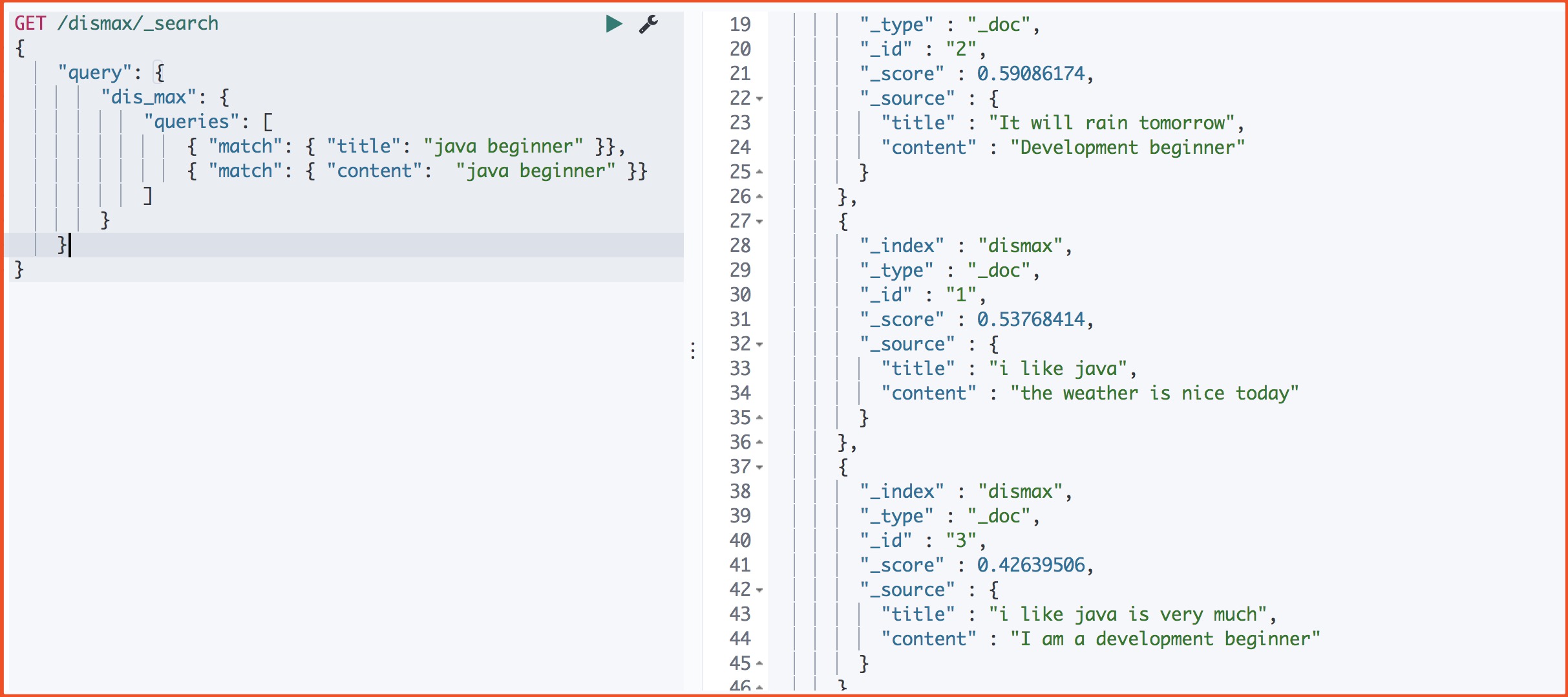
我们可以很明显看出: 只是取分数最高的那个query的分数排序。
doc1:title: 0.53 ; content: 0 = 0.53
doc2:title:0 ; content:0.59 = 0,59
doc3:title:0.41 ; content:0.42 = 0.42
所以这里的排序为 2 – 1 – 3
3)dis_max查询(不带tie_breaker)
1 | #运行结果 3-2-1 |
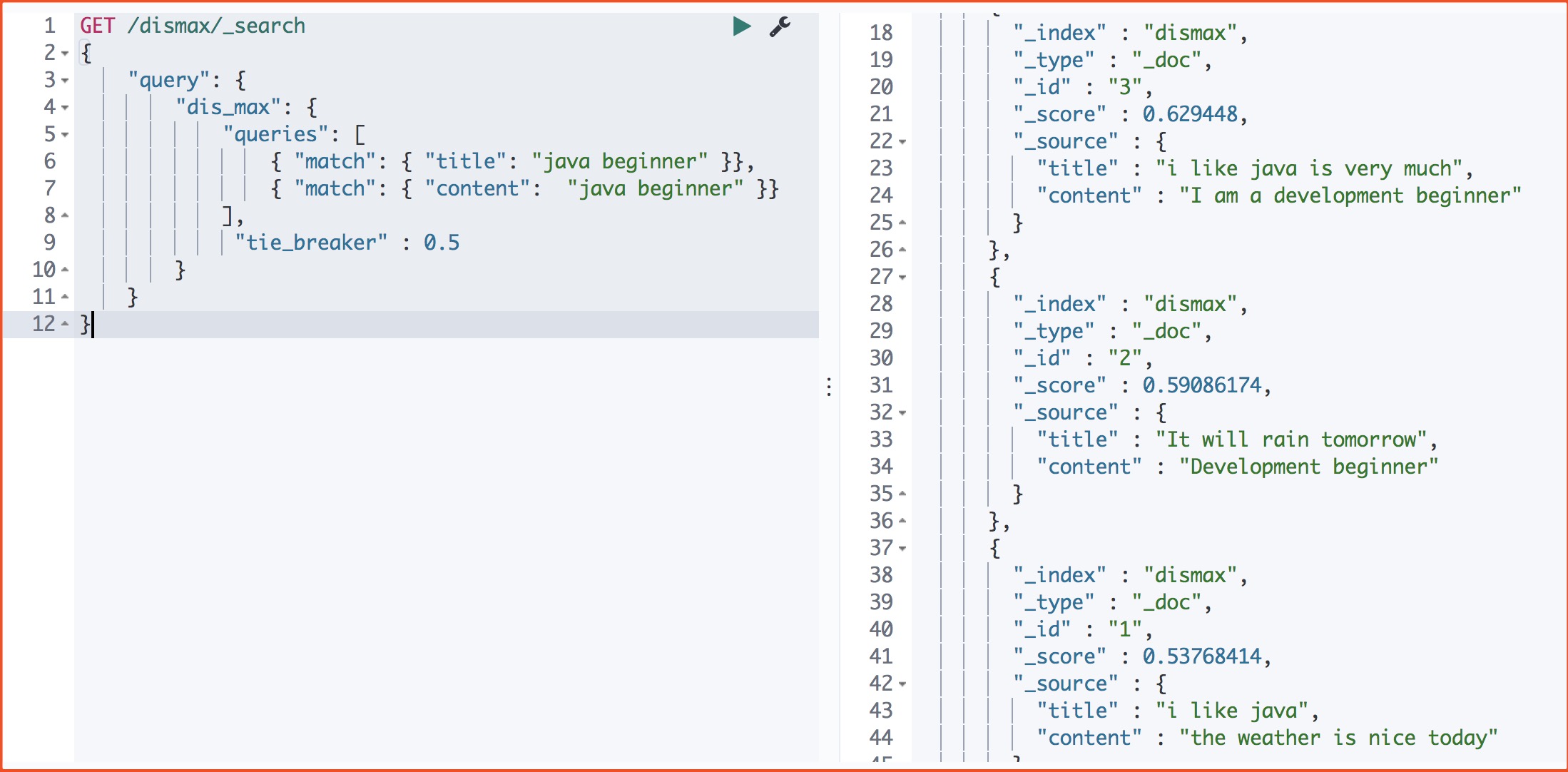
这里可以看出看出: 取分数最高的那个query的分数,同时其它子查询查询的分数乘以tie_breaker
doc1:title: 0.53 + content: 0 = 0.53
doc2:title:0 + content:0.59 = 0,59
doc3:title:0.41 + content:0.42*0.5 = 0.62
所以这里的排序为 3 – 2 – 1
五、function_score(函数查询)
1、概念
1 | 定义` function_score是处理分值计算过程的终极工具。它让你能够对所有匹配了主查询的每份文档`调用一个函数来调整甚至是完全替换原来的_score。 |
注意 要使用function_score,用户必须定义一个查询和一个或多个函数,这些函数计算查询返回的每个文档的新分数。
它拥有几种预先定义好了的函数:
weight 对每份文档适用一个简单的提升,且该提升不会被归约:当weight为2时,结果为2 * _score。
field_value_factor 使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内。
random_score 使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式。
1 | 衰减函数(Decay Function) - linear,exp,gauss |
将像publish_date,geo_location或者price这类浮动值考虑到_score中,偏好最近发布的文档,邻近于某个地理位置(译注:其中的某个字段)的文档或者价格
(译注:其中的某个字段)靠近某一点的文档。
1 | script_score |
使用自定义的脚本来完全控制分值计算逻辑。如果你需要以上预定义函数之外的功能,可以根据需要通过脚本进行实现。
2)使用场景
有关function_score如果要深入讲,估计一篇博客都不够,所以这里说下在现实中可能会用的场景,如果你有这些场景,那么就可以考虑用function_score。
1 | 1)假设我们又一个资讯类APP我们希望让人阅读量高的文章出现在结果列表的头部,但是主要的排序依据仍然是全文搜索分值。 |
有关function_score例子这里就不写了,具体的可以参考官方文档:Function score query
...
...
This is copyright.