缓存简介
随着互联网的普及,内容信息越来越复杂,用户数和访问量越来越大,我们的应用需要支撑更多的并发量,同时我们的应用服务器和数据库服务器所做的计算也越来越多。但是往往我们的应用服务器资源是有限的,且技术变革是缓慢的,数据库每秒能接受的请求次数也是有限的(或者文件的读写也是有限的),如何能够有效利用有限的资源来提供尽可能大的吞吐量? 一个有效的办法就是引入缓存,打破标准流程,每个环节中请求可以从缓存中直接获取目标数据并返回,从而减少计算量,有效提升响应速度,让有限的资源服务更多的用户。
缓存的应用和实现
缓存有各类特征,而且有不同介质的区别,那么实际工程中我们怎么去对缓存分类呢? 在目前的应用服务框架中,比较常见的是根据缓存与应用的藕合度,分为local cache(本地缓存)和remote cache(分布式缓存):
- 本地缓存:指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适;同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
- 分布式缓存:指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
目前各种类型的缓存都活跃在成千上万的应用服务中,还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。缓存的使用是程序员、架构师的必备技能,好的程序员能根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
缓存实现-本地缓存
编程直接实现缓存 个别场景下,我们只需要简单的缓存数据的功能,而无需关注更多存取、清空策略等深入的特性时,直接编程实现缓存则是最便捷和高效的。
1. 成员变量或局部变量实现
以局部变量map结构缓存部分业务数据,减少频繁的重复数据库I/O操作。缺点仅限于类的自身作用域内,类间无法共享缓存。
示例代码:
1 | public calss DbService { |
使用ImmutableMap避免map被修改
1 |
|
2.静态变量实现
最常用的单例实现静态资源缓存,代码示例如下:
1 |
|
3.JetCache @CreateCache实现
JetCache官网wiki文档:https://github.com/alibaba/jetcache/wiki
创建缓存实例
1 |
|
创建方法缓存
使用@Cached方法可以为一个方法添加上缓存。JetCache通过Spring AOP生成代理,来支持缓存功能。注解可以加在接口方法上也可以加在类方法上,但需要保证是个Spring bean。
1 | public interface UserService { |
4. Guava Cache实现
Guava Cache是Google开源的Java重用工具集库Guava里的一款缓存工具,其主要实现的缓存功能有:
- 自动将entry节点加载进缓存结构中;
- 当缓存的数据超过设置的最大值时,使用LRU算法移除;
- 具备根据entry节点上次被访问或者写入时间计算它的过期机制;
- 缓存的key被封装在WeakReference引用内;
- 缓存的Value被封装在WeakReference或SoftReference引用内;
- 统计缓存使用过程中命中率、异常率、未命中率等统计数据。
Guava Cache的架构设计灵感来源于ConcurrentHashMap,我们前面也提到过,简单场景下可以自行编码通过hashmap来做少量数据的缓存,但是,如果结果可能随时间改变或者是希望存储的数据空间可控的话,自己实现这种数据结构还是有必要的。
Guava Cache继承了ConcurrentHashMap的思路,使用多个segments方式的细粒度锁,在保证线程安全的同时,支持高并发场景需求。Cache类似于Map,它是存储键值对的集合,不同的是它还需要处理evict、expire、dynamic load等算法逻辑,需要一些额外信息来实现这些操作。对此,根据面向对象思想,需要做方法与数据的关联封装。如图5所示cache的内存数据模型,可以看到,使用ReferenceEntry接口来封装一个键值对,而用ValueReference来封装Value值,之所以用Reference命令,是因为Cache要支持WeakReference Key和SoftReference、WeakReference value。

图1 Guava Cache数据结构图
ReferenceEntry是对一个键值对节点的抽象,它包含了key和值的ValueReference抽象类,Cache由多个Segment组成,而每个Segment包含一个ReferenceEntry数组,每个ReferenceEntry数组项都是一条ReferenceEntry链,且一个ReferenceEntry包含key、hash、valueReference、next字段。除了在ReferenceEntry数组项中组成的链,在一个Segment中,所有ReferenceEntry还组成access链(accessQueue)和write链(writeQueue)(后面会介绍链的作用)。ReferenceEntry可以是强引用类型的key,也可以WeakReference类型的key,为了减少内存使用量,还可以根据是否配置了expireAfterWrite、expireAfterAccess、maximumSize来决定是否需要write链和access链确定要创建的具体Reference:StrongEntry、StrongWriteEntry、StrongAccessEntry、StrongWriteAccessEntry等。
对于ValueReference,因为Cache支持强引用的Value、SoftReference Value以及WeakReference Value,因而它对应三个实现类:StrongValueReference、SoftValueReference、WeakValueReference。为了支持动态加载机制,它还有一个LoadingValueReference,在需要动态加载一个key的值时,先把该值封装在LoadingValueReference中,以表达该key对应的值已经在加载了,如果其他线程也要查询该key对应的值,就能得到该引用,并且等待改值加载完成,从而保证该值只被加载一次,在该值加载完成后,将LoadingValueReference替换成其他ValueReference类型。ValueReference对象中会保留对ReferenceEntry的引用,这是因为在Value因为WeakReference、SoftReference被回收时,需要使用其key将对应的项从Segment的table中移除。
WriteQueue和AccessQueue :为了实现最近最少使用算法,Guava Cache在Segment中添加了两条链:write链(writeQueue)和access链(accessQueue),这两条链都是一个双向链表,通过ReferenceEntry中的previousInWriteQueue、nextInWriteQueue和previousInAccessQueue、nextInAccessQueue链接而成,但是以Queue的形式表达。WriteQueue和AccessQueue都是自定义了offer、add(直接调用offer)、remove、poll等操作的逻辑,对offer(add)操作,如果是新加的节点,则直接加入到该链的结尾,如果是已存在的节点,则将该节点链接的链尾;对remove操作,直接从该链中移除该节点;对poll操作,将头节点的下一个节点移除,并返回。
了解了cache的整体数据结构后,再来看下针对缓存的相关操作就简单多了:
- Segment中的evict清除策略操作,是在每一次调用操作的开始和结束时触发清理工作,这样比一般的缓存另起线程监控清理相比,可以减少开销,但如果长时间没有调用方法的话,会导致不能及时的清理释放内存空间的问题。evict主要处理四个Queue:1. keyReferenceQueue;2. valueReferenceQueue;3. writeQueue;4. accessQueue。前两个queue是因为WeakReference、SoftReference被垃圾回收时加入的,清理时只需要遍历整个queue,将对应的项从LocalCache中移除即可,这里keyReferenceQueue存放ReferenceEntry,而valueReferenceQueue存放的是ValueReference,要从Cache中移除需要有key,因而ValueReference需要有对ReferenceEntry的引用,这个前面也提到过了。而对后面两个Queue,只需要检查是否配置了相应的expire时间,然后从头开始查找已经expire的Entry,将它们移除即可。
- Segment中的put操作:put操作相对比较简单,首先它需要获得锁,然后尝试做一些清理工作,接下来的逻辑类似ConcurrentHashMap中的rehash,查找位置并注入数据。需要说明的是当找到一个已存在的Entry时,需要先判断当前的ValueRefernece中的值事实上已经被回收了,因为它们可以是WeakReference、SoftReference类型,如果已经被回收了,则将新值写入。并且在每次更新时注册当前操作引起的移除事件,指定相应的原因:COLLECTED、REPLACED等,这些注册的事件在退出的时候统一调用Cache注册的RemovalListener,由于事件处理可能会有很长时间,因而这里将事件处理的逻辑在退出锁以后才做。最后,在更新已存在的Entry结束后都尝试着将那些已经expire的Entry移除。另外put操作中还需要更新writeQueue和accessQueue的语义正确性。
- Segment带CacheLoader的get操作:1. 先查找table中是否已存在没有被回收、也没有expire的entry,如果找到,并在CacheBuilder中配置了refreshAfterWrite,并且当前时间间隔已经操作这个事件,则重新加载值,否则,直接返回原有的值;2. 如果查找到的ValueReference是LoadingValueReference,则等待该LoadingValueReference加载结束,并返回加载的值;3. 如果没有找到entry,或者找到的entry的值为null,则加锁后,继续在table中查找已存在key对应的entry,如果找到并且对应的entry.isLoading()为true,则表示有另一个线程正在加载,因而等待那个线程加载完成,如果找到一个非null值,返回该值,否则创建一个LoadingValueReference,并调用loadSync加载相应的值,在加载完成后,将新加载的值更新到table中,即大部分情况下替换原来的LoadingValueReference。
Guava Cache提供Builder模式的CacheBuilder生成器来创建缓存的方式,十分方便,并且各个缓存参数的配置设置,类似于函数式编程的写法,可自行设置各类参数选型。它提供三种方式加载到缓存中。分别是:
- 在构建缓存的时候,使用build方法内部调用CacheLoader方法加载数据;
- callable 、callback方式加载数据;
- 使用粗暴直接的方式,直接Cache.put 加载数据,但自动加载是首选的,因为它可以更容易的推断所有缓存内容的一致性。
build生成器的两种方式都实现了一种逻辑:从缓存中取key的值,如果该值已经缓存过了则返回缓存中的值,如果没有缓存过可以通过某个方法来获取这个值,不同的地方在于cacheloader的定义比较宽泛,是针对整个cache定义的,可以认为是统一的根据key值load value的方法,而callable的方式较为灵活,允许你在get的时候指定load方法。使用示例如下:
1 | /** |
总体来看,Guava Cache基于ConcurrentHashMap的优秀设计借鉴,在高并发场景支持和线程安全上都有相应的改进策略,使用Reference引用命令,提升高并发下的数据……访问速度并保持了GC的可回收,有效节省空间;同时,write链和access链的设计,能更灵活、高效的实现多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等;编程式的build生成器管理,让使用者有更多的自由度,能够根据不同场景设置合适的模式。
缓存实现-分布式缓存
redis实现
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。同时性能强劲,具有复制特性以及解决问题而生的独一无二的数据模型。它可以存储键值对与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘,可以使用复制特性来扩展读性能,还可以使用客户端分片来扩展写性能。

图2 Redis数据模型图
如图2,Redis内部使用一个redisObject对象来标识所有的key和value数据,redisObject最主要的信息如图所示:type代表一个value对象具体是何种数据类型,encoding是不同数据类型在Redis内部的存储方式,比如——type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或是int,如果是int则代表世界Redis内部是按数值类型存储和表示这个字符串。
图2左边的raw列为对象的编码方式:字符串可以被编码为raw(一般字符串)或Rint(为了节约内存,Redis会将字符串表示的64位有符号整数编码为整数来进行储存);列表可以被编码为ziplist或linkedlist,ziplist是为节约大小较小的列表空间而作的特殊表示;集合可以被编码为intset或者hashtable,intset是只储存数字的小集合的特殊表示;hash表可以编码为zipmap或者hashtable,zipmap是小hash表的特殊表示;有序集合可以被编码为ziplist或者skiplist格式,ziplist用于表示小的有序集合,而skiplist则用于表示任何大小的有序集合。
从网络I/O模型上看,Redis使用单线程的I/O复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll、kqueue和select。对于单纯只有I/O操作来说,单线程可以将速度优势发挥到最大,但是Redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU计算过程中,整个I/O调度都是被阻塞住的,在这些特殊场景的使用中,需要额外的考虑。相较于memcached的预分配内存管理,Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片。Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据)。
我们描述Redis为内存数据库,作为缓存服务,大量使用内存间的数据快速读写,支持高并发大吞吐;而作为数据库,则是指Redis对缓存的持久化支持。Redis由于支持了非常丰富的内存数据库结构类型,如何把这些复杂的内存组织方式持久化到磁盘上? Redis的持久化与传统数据库的方式差异较大,Redis一共支持四种持久化方式,主要使用的两种:
- 定时快照方式(snapshot):该持久化方式实际是在Redis内部一个定时器事件,每隔固定时间去检查当前数据发生的改变次数与时间是否满足配置的持久化触发的条件,如果满足则通过操作系统fork调用来创建出一个子进程,这个子进程默认会与父进程共享相同的地址空间,这时就可以通过子进程来遍历整个内存来进行存储操作,而主进程则仍然可以提供服务,当有写入时由操作系统按照内存页(page)为单位来进行copy-on-write保证父子进程之间不会互相影响。它的缺点是快照只是代表一段时间内的内存映像,所以系统重启会丢失上次快照与重启之间所有的数据。
- 基于语句追加文件的方式(aof):aof方式实际类似MySQl的基于语句的binlog方式,即每条会使Redis内存数据发生改变的命令都会追加到一个log文件中,也就是说这个log文件就是Redis的持久化数据。 aof的方式的主要缺点是追加log文件可能导致体积过大,当系统重启恢复数据时如果是aof的方式则加载数据会非常慢,几十G的数据可能需要几小时才能加载完,当然这个耗时并不是因为磁盘文件读取速度慢,而是由于读取的所有命令都要在内存中执行一遍。另外由于每条命令都要写log,所以使用aof的方式,Redis的读写性能也会有所下降。
Redis的持久化使用了Buffer I/O,所谓Buffer I/O是指Redis对持久化文件的写入和读取操作都会使用物理内存的Page Cache,而大多数数据库系统会使用Direct I/O来绕过这层Page Cache并自行维护一个数据的Cache。而当Redis的持久化文件过大(尤其是快照文件),并对其进行读写时,磁盘文件中的数据都会被加载到物理内存中作为操作系统对该文件的一层Cache,而这层Cache的数据与Redis内存中管理的数据实际是重复存储的。虽然内核在物理内存紧张时会做Page Cache的剔除工作,但内核很可能认为某块Page Cache更重要,而让你的进程开始Swap,这时你的系统就会开始出现不稳定或者崩溃了,因此在持久化配置后,针对内存使用需要实时监控观察。
与memcached客户端支持分布式方案不同,Redis更倾向于在服务端构建分布式存储,如图10、11。
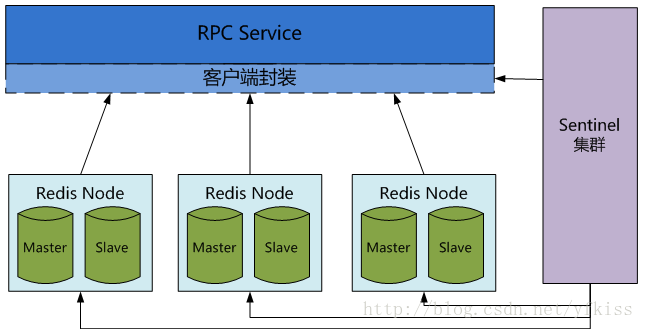

Redis Cluster是一个实现了分布式且允许单点故障的Redis高级版本,它没有中心节点,具有线性可伸缩的功能。如图11,其中节点与节点之间通过二进制协议进行通信,节点与客户端之间通过ascii协议进行通信。在数据的放置策略上,Redis Cluster将整个key的数值域分成2的14次方16384个hash槽,每个节点上可以存储一个或多个hash槽,也就是说当前Redis Cluster支持的最大节点数就是16384。Redis Cluster使用的分布式算法也很简单:crc16( key ) % HASH_SLOTS_NUMBER。整体设计可总结为:
- 数据hash分布在不同的Redis节点实例上;
- M/S的切换采用Sentinel;
- 写:只会写master Instance,从sentinel获取当前的master Instance;
- 读:从Redis Node中基于权重选取一个Redis Instance读取,失败/超时则轮询其他Instance;Redis本身就很好的支持读写分离,在单进程的I/O场景下,可以有效的避免主库的阻塞风险;
redis缓存淘汰策略
Redis共支持八种淘汰策略,分别是noeviction、volatile-random、volatile-ttl、volatile-lru、volatile-lfu、allkeys-lru、allkeys-random 和 allkeys-lfu 策略。
分类:
不淘汰
- noeviction (v4.0后默认的)
对设置了过期时间的数据中进行淘汰
- 随机:volatile-random
- ttl:volatile-ttl
- lru:volatile-lru
- lfu:volatile-lfu
全部数据进行淘汰
- 随机:allkeys-random
- lru:allkeys-lru
- lfu:allkeys-lfu
淘汰策略详细说明:
- noeviction
该策略是Redis的默认策略。在这种策略下,一旦缓存被写满了,再有写请求来时,Redis 不再提供服务,而是直接返回错误。这种策略不会淘汰数据,所以无法解决缓存污染问题。一般生产环境不建议使用。
其他七种规则都会根据自己相应的规则来选择数据进行删除操作。
- volatile-random
这个算法比较简单,在设置了过期时间的键值对中,进行随机删除。因为是随机删除,无法把不再访问的数据筛选出来,所以可能依然会存在缓存污染现象,无法解决缓存污染问题。
- volatile-ttl
这种算法判断淘汰数据时参考的指标比随机删除时多进行一步过期时间的排序。Redis在筛选需删除的数据时,越早过期的数据越优先被选择。
- volatile-lru
LRU算法:LRU 算法的全称是 Least Recently Used,按照最近最少使用的原则来筛选数据。这种模式下会使用 LRU 算法筛选设置了过期时间的键值对。
Redis优化的LRU算法实现:
Redis会记录每个数据的最近一次被访问的时间戳。在Redis在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。通过随机读取待删除集合,可以让Redis不用维护一个巨大的链表,也不用操作链表,进而提升性能。
Redis 选出的数据个数 N,通过 配置参数 maxmemory-samples 进行配置。个数N越大,则候选集合越大,选择到的最久未被使用的就更准确,N越小,选择到最久未被使用的数据的概率也会随之减小。
- volatile-lfu
会使用 LFU 算法选择设置了过期时间的键值对。
LFU 算法:LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。 Redis的LFU算法实现:
当 LFU 策略筛选数据时,Redis 会在候选集合中,根据数据 lru 字段的后 8bit 选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据 lru 字段的前 16bit 值大小,选择访问时间最久远的数据进行淘汰。
Redis 只使用了 8bit 记录数据的访问次数,而 8bit 记录的最大值是 255,这样在访问快速的情况下,如果每次被访问就将访问次数加一,很快某条数据就达到最大值255,可能很多数据都是255,那么退化成LRU算法了。所以Redis为了解决这个问题,实现了一个更优的计数规则,并可以通过配置项,来控制计数器增加的速度。
参数 :
lfu-log-factor ,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
lfu-decay-time, 控制访问次数衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
lfu-log-factor设置越大,递增概率越低,lfu-decay-time设置越大,衰减速度会越慢。
我们在应用 LFU 策略时,一般可以将 lfu_log_factor 取值为 10。 如果业务应用中有短时高频访问的数据的话,建议把 lfu_decay_time 值设置为 1。可以快速衰减访问次数。
volatile-lfu 策略是 Redis 4.0 后新增。
- allkeys-lru
使用 LRU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lru 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
- allkeys-random
从所有键值对中随机选择并删除数据。volatile-random 跟 allkeys-random算法一样,随机删除就无法解决缓存污染问题。
- allkeys-lfu
使用 LFU 算法在所有数据中进行筛选。具体LFU算法跟上述 volatile-lfu 中介绍的一致,只是筛选的数据范围是全部缓存,这里就不在重复。
allkeys-lfu 策略是 Redis 4.0 后新增。
数据库和缓存一致性问题
同步策略
保证缓存和数据库的双写一致性,共有四种同步策略
- 先更新缓存 再更新数据库
- 先更新数据库 再更新缓存
- 先删除缓存 再更新数据库
- 先更新数据库 再删除缓存
更新缓存与删除缓存的选择
更新缓存的优点是每次数据变化时都能及时地更新缓存,这样不容易出现查询未命中的情况,但这种操作的消耗很大,如果数据需要经过复杂的计算再写入缓存的话,频繁的更新缓存会影响到服务器的性能。如果是写入数据比较频繁的场景,可能会导致频繁的更新缓存却没有业务来读取该数据。
删除缓存的优点是操作简单,无论更新的操作复杂与否,都是直接删除缓存中的数据。这种做法的缺点则是,当删除了缓存之后,下一次查询容易出现未命中的情况,那么这时就需要再次读取数据库。
从缓存利用率的角度分析,不应该选择更新缓存方案。如果数据需要经过复杂的计算再写入缓存的话,频繁的更新缓存会影响到服务器的性能,且每次更新的缓存可能未被读取又进行了更新,缓存数据中还可能存放了很多不常用数据,浪费缓存资源。
先操作数据库与后操作数据库的选择
第一步执行成功,第二步执行失败
1) 先删除缓存,后更新数据库
删除缓存成功后,数据库更新失败会导致新的读缓存请求读不到,重新读未更新的库,依然获取到的是删除缓存前的数据。
2) 先更新数据库,后删除缓存
先更新数据库再删除缓存,删除缓存失败会导致在缓存有效的期限内,所有读缓存的请求获取到的依旧是更新数据库前的数据。
并发执行问题
1) 先删除缓存,后更新数据库
如果有 2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
可见,先删除缓存,后更新数据库,当发生「读+写」并发时,还是存在数据不一致的情况。
2) 先更新数据库,后删除缓存
依旧是 2 个线程并发「读写」数据:
- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
这种情况「理论」来说是可能发生的,但实际真的有可能发生吗?
其实概率「很低」,这是因为它必须满足 3 个条件:
- 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间短(步骤 2 和 5)
仔细想一下,条件 3 发生的概率其实是非常低的。
因为写数据库一般会先「加锁」,所以写数据库,通常是要比读数据库的时间更长的。
这么来看,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
所以,我们应该采用这种方案,来操作数据库和缓存。
如何保证两步都执行成功
前面我们分析到,无论是更新缓存还是删除缓存,只要第二步发生失败,那么就会导致数据库和缓存不一致。
保证第二步成功执行,就是解决问题的关键。
想一下,程序在执行过程中发生异常,最简单的解决办法是什么?
答案是:重试。
是的,其实这里我们也可以这样做。
无论是先操作缓存,还是先操作数据库,但凡后者执行失败了,我们就可以发起重试,尽可能地去做「补偿」。
那这是不是意味着,只要执行失败,我们「无脑重试」就可以了呢?
答案是否定的。现实情况往往没有想的这么简单,失败后立即重试的问题在于:
- 立即重试很大概率「还会失败」
- 「重试次数」设置多少才合理?
- 重试会一直「占用」这个线程资源,无法服务其它客户端请求
看到了么,虽然我们想通过重试的方式解决问题,但这种「同步」重试的方案依旧不严谨。
那更好的方案应该怎么做?
答案是:异步重试。什么是异步重试?
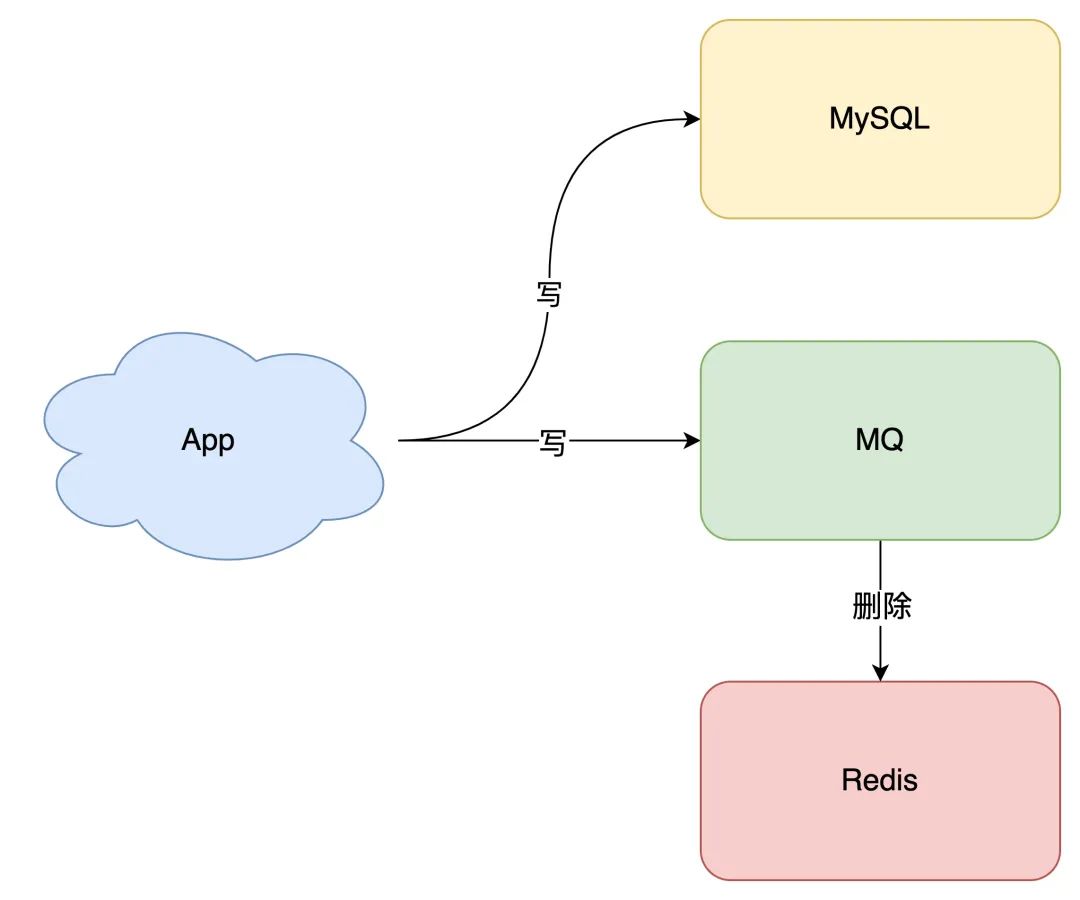
其实就是把重试请求写到「消息队列」中,然后由专门的消费者来重试,直到成功。
或者更直接的做法,为了避免第二步执行失败,我们可以把操作缓存这一步,直接放到消息队列中,由消费者来操作缓存。
到这里你可能会问,写消息队列也有可能会失败啊?而且,引入消息队列,这又增加了更多的维护成本,这样做值得吗?
这个问题很好,但我们思考这样一个问题:如果在执行失败的线程中一直重试,还没等执行成功,此时如果项目「重启」了,那这次重试请求也就「丢失」了,那这条数据就一直不一致了。
所以,这里我们必须把重试或第二步操作放到另一个「服务」中,这个服务用「消息队列」最为合适。这是因为消息队列的特性,正好符合我们的需求:
- 消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)
- 消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)
至于写队列失败和消息队列的维护成本问题:
- 写队列失败:操作缓存和写消息队列,「同时失败」的概率其实是很小的
- 维护成本:我们项目中一般都会用到消息队列,维护成本并没有新增很多
所以,引入消息队列来解决这个问题,是比较合适的。这时架构模型就变成了这样:
那如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?
方案还是有的,这就是近几年比较流行的解决方案:订阅数据库变更日志,再操作缓存。
具体来讲就是,我们的业务应用在修改数据时,「只需」修改数据库,无需操作缓存。
那什么时候操作缓存呢?这就和数据库的「变更日志」有关了。
拿 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
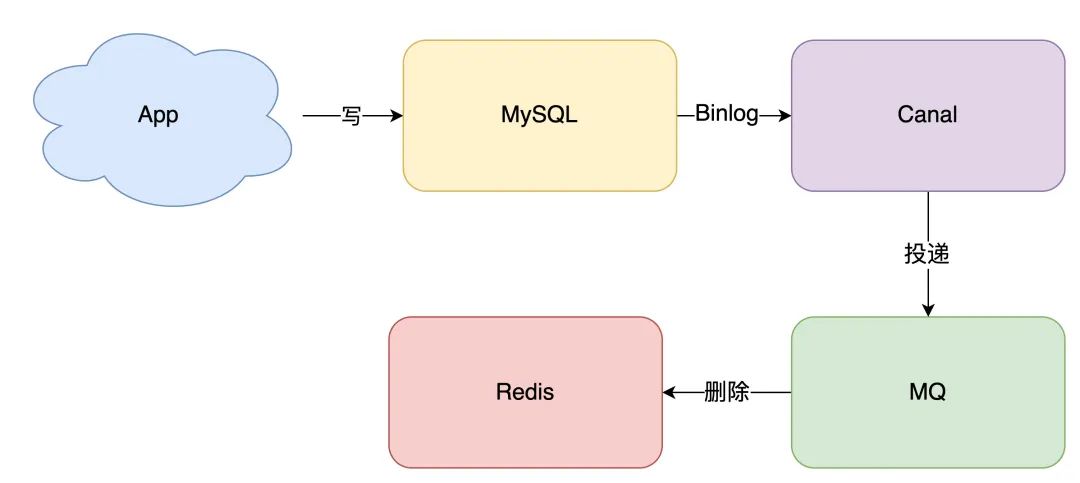
订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,使用这种方案的优点在于:
- 无需考虑写消息队列失败情况:只要写 MySQL 成功,Binlog 肯定会有
- 自动投递到下游队列:canal 自动把数据库变更日志「投递」给下游的消息队列
当然,与此同时,我们需要投入精力去维护 canal 的高可用和稳定性。
如果你有留意观察很多数据库的特性,就会发现其实很多数据库都逐渐开始提供「订阅变更日志」的功能了,相信不远的将来,我们就不用通过中间件来拉取日志,自己写程序就可以订阅变更日志了,这样可以进一步简化流程。
至此,我们可以得出结论,想要保证数据库和缓存一致性,推荐采用「先更新数据库,再删除缓存」方案,并配合「消息队列」或「订阅变更日志」的方式来做。
数据库和缓存可以做到强一致吗
要想做到强一致,最常见的方案是 2PC、3PC、Paxos、Raft 这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。
相反,这时我们换个角度思考一下,我们引入缓存的目的是什么?
没错,性能。
一旦我们决定使用缓存,那必然要面临一致性问题。性能和一致性就像天平的两端,无法做到都满足要求。
而且,就拿我们前面讲到的方案来说,当操作数据库和缓存完成之前,只要有其它请求可以进来,都有可能查到「中间状态」的数据。
所以如果非要追求强一致,那必须要求所有更新操作完成之前期间,不能有「任何请求」进来。
虽然我们可以通过加「分布锁」的方式来实现,但我们要付出的代价,很可能会超过引入缓存带来的性能提升。
所以,既然决定使用缓存,就必须容忍「一致性」问题,我们只能尽可能地去降低问题出现的概率。
同时我们也要知道,缓存都是有「失效时间」的,就算在这期间存在短期不一致,我们依旧有失效时间来兜底,这样也能达到最终一致。
参考资料
- https://www.pdai.tech/md/arch/arch-y-cache.html
- https://mp.weixin.qq.com/s/D4Ik6lTA_ySBOyD3waNj1w
- https://www.moguit.cn/cInfo/2936?title=%E9%9D%A2%E7%BB%8F
...
...
This is copyright.